用GitHub仓库做书签和AI摘要-流动知识检索
Oct 12, 2024 · 2377 words · 5 min · #Input #Github #Python
AI摘要正在生成中……
GitHub 书签#
看到了LLM x 书签收藏:摘要 & 全文索引 - Nekonull’s Garden这篇文章,思路很值得借鉴,通过GitHub Actions来总结网页文章内容并写入到GitHub仓库里。
之前在思考流动知识检索的时候,完全没有想到利用GitHub Actions来构建workflow。
大致流程是:通过osmos::memo 书签插件,将网页文章的链接以MD格式保存到GitHub仓库,然后利用GitHub Actions读取这些链接用LLM做总结并保存到另一个bookmark-summary仓库。
作者的主要思路:
为了解决这些问题,我建立了一个新的存储库 bookmark-summary。这个存储库可以视为现有书签存储库的辅助数据,其中包含了新增书签的 Markdown 格式全文、列表摘要、一句话总结,和现有存储库之间通过 Github Actions 联动。其工作原理如下:
我通过书签插件,在现有的书签存储库中新增了一个条目
代码提交到主干,触发名为
summarize的 Github Actions(yml 工作流文件)Github Actions 执行,首先 checkout 书签存储库和摘要存储库,然后执行
process_changes.py
- 首先解析书签 README.md 文件,找到最近新增的条目标题和 URL
- 将 URL 保存到 Wayback Machine
- 输入 URL,使用 jina reader API 获取网址的 Markdown 全文,并保存到
YYYYMM/{title}_raw.md- 输入 URL,使用 LLM 生成列表摘要(prompt 在
summarize_text函数 link)- 输入列表摘要,使用 LLM 生成一句话总结
- 将列表摘要和一句话总结保存到
YYYYMM/{title}.md(效果示例)- 更新摘要存储库的 README.md,增加到摘要文件的链接
Github Actions 提交变更到摘要存储库
我跟着文章跑着试了一下,效果挺好的:
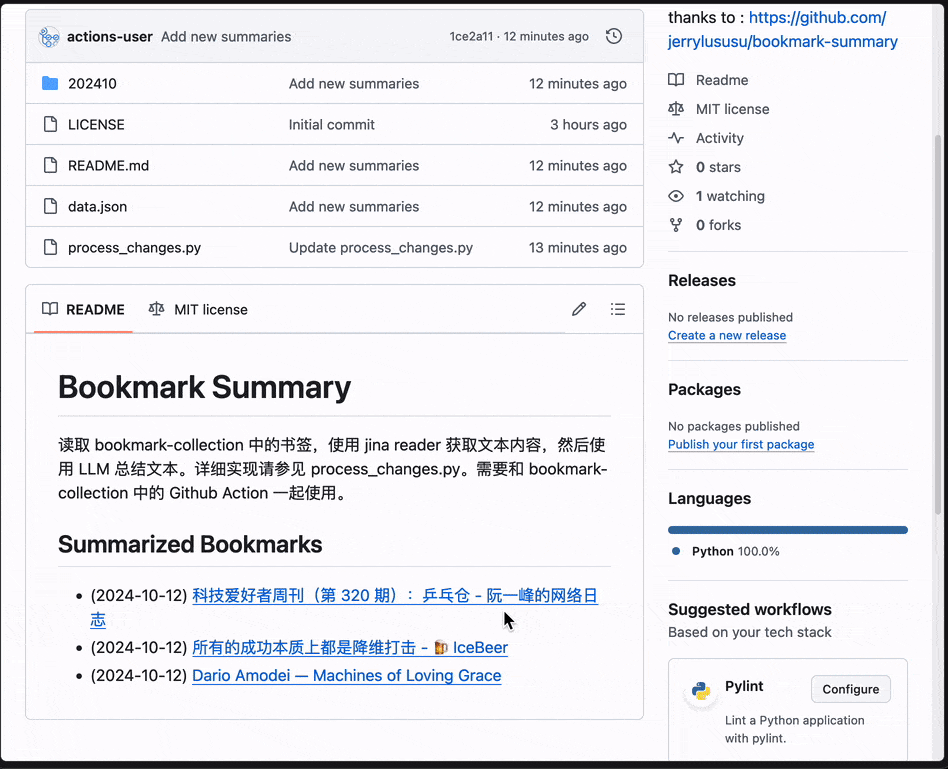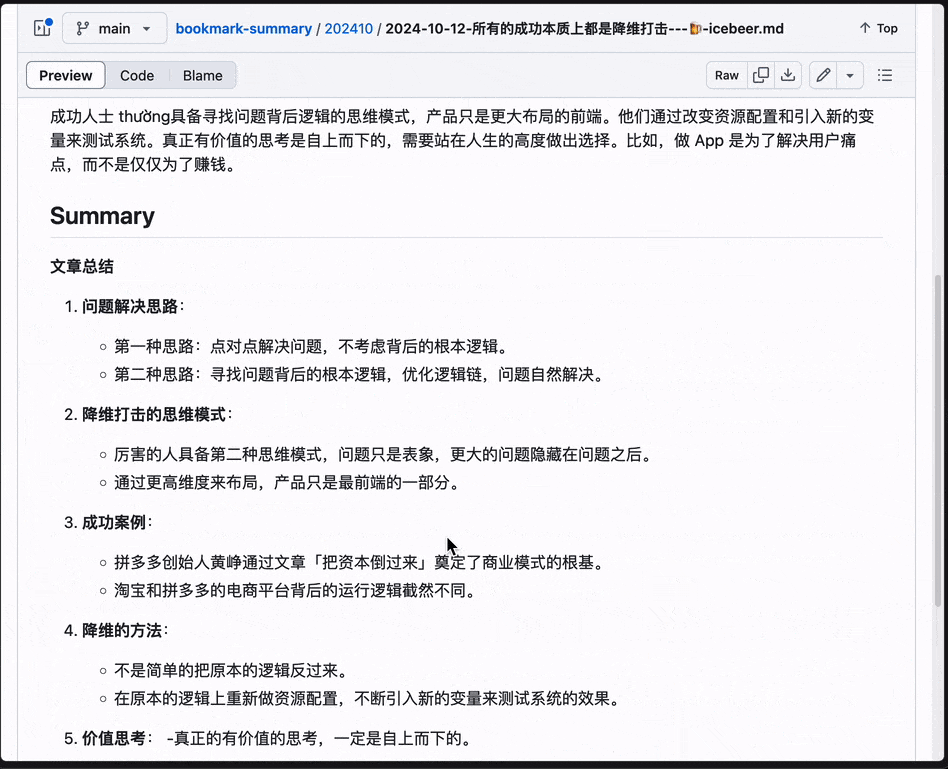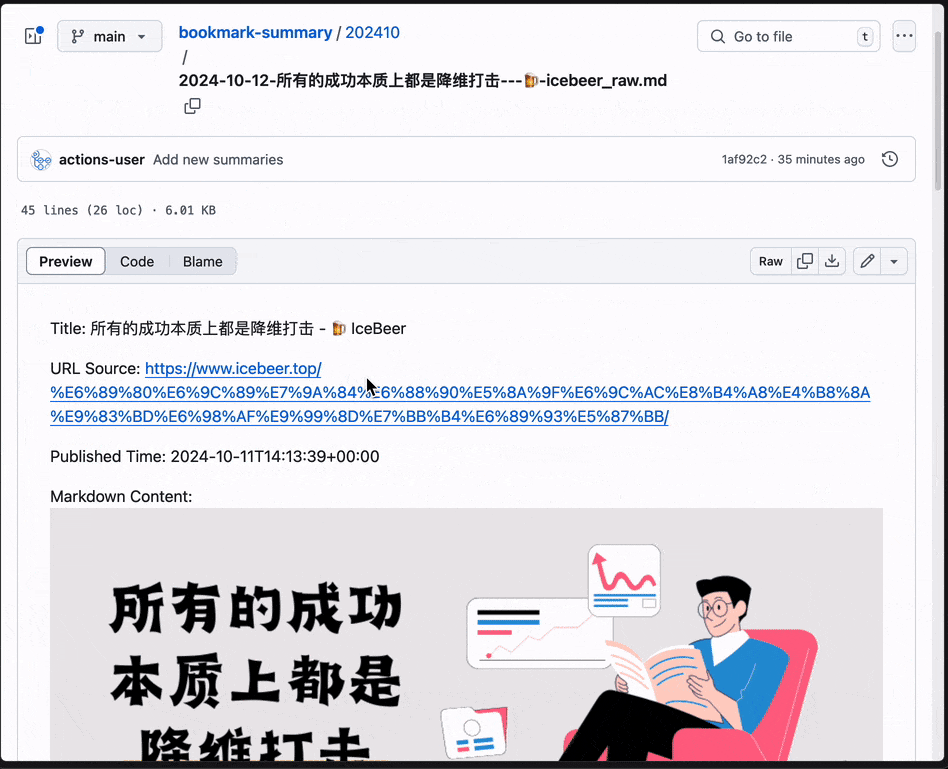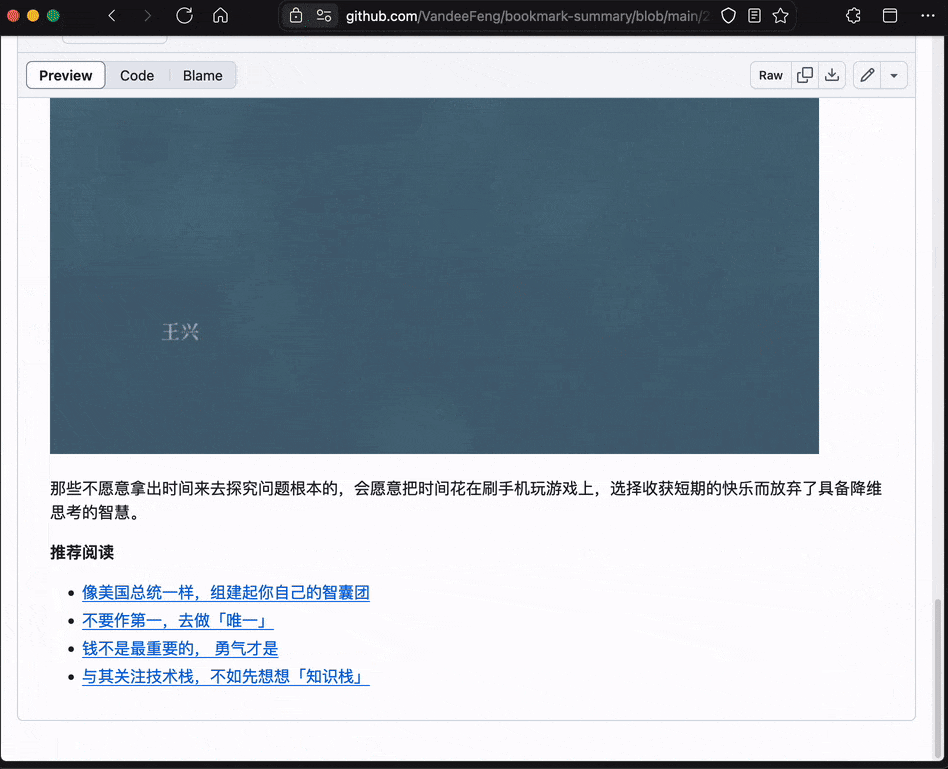
Github Actions里模型、总结的prompt、输出的格式和方式都可以根据自己的需求修改。
有一个小问题正好别人也遇到了,运行process_changes.py的时候由于要读取data.json文件,而初始文件没有内容,加上一个{}空字典就好了。可以在脚本里优化一下这个过程,如果没有data.json或者data.json文件为空自动写入数据。
对我来说,这个保存书签bookmark和总结的workflow特别适合那些不痛不痒的文章,有些亮点但又不那么惊艳,丢掉又有点可惜,或者是纯记录价值的文章,对我特别有价值的都直接记录在我的PKM里了。再一个,备份数据是一个很好的习惯,关键素材被删!找不到素材?影视飓风是如何摆脱丢数据噩梦的:三备二介异地。就是一个数据备份3次,储存在2种介质当中,并且保证有一份完整的数据在异地,可以简称3-2-1原则了。
之前尝试过archivebox,就是个可以自己部署的Internet Archive。开源免费,支持docker,但这个项目太大了,作者这个轻巧的方案现在正符合我的需求。
日常的阅读我现在基本都在Readwise了,这个workflow后面还可以和RAG结合起来,作为我流动知识的检索的数据库。后面想到什么好点子再融合进来,这个项目是一个很好的思路和模板,感谢作者的分享。
我去掉了作者保存到 Wayback Machine(Internet Archive)的这一步,更改了按年份、月份保存文件,下面是修改后process_changes.py的完整代码:
import re
from typing import List, Optional
import requests
import json
from datetime import datetime
from pathlib import Path
from dataclasses import dataclass, asdict
import os
import logging
import time
from functools import wraps
from urllib.parse import quote
# -- configurations begin --
BOOKMARK_COLLECTION_REPO_NAME: str = "bookmark-collection"
BOOKMARK_SUMMARY_REPO_NAME: str = "bookmark-summary"
# -- configurations end --
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
def log_execution_time(func):
@wraps(func)
def wrapper(*args, **kwargs):
logging.info(f'Entering {func.__name__}')
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f'Exiting {func.__name__} - Elapsed time: {elapsed_time:.4f} seconds')
return result
return wrapper
@dataclass
class SummarizedBookmark:
year: str
month: str # yyyyMM
title: str
url: str
timestamp: int # unix timestamp
CURRENT_YEAR: str = datetime.now().strftime('%Y')
CURRENT_MONTH: str = datetime.now().strftime('%m')
CURRENT_DATE: str = datetime.now().strftime('%Y-%m-%d')
CURRENT_DATE_AND_TIME: str = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
@log_execution_time
def get_text_content(url: str) -> str:
jina_url: str = f"https://r.jina.ai/{url}"
response: requests.Response = requests.get(jina_url)
return response.text
@log_execution_time
def call_openai_api(prompt: str, content: str) -> str:
model: str = os.environ.get('OPENAI_API_MODEL', 'gpt-4o-mini')
headers: dict = {
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
"Content-Type": "application/json"
}
data: dict = {
"model": model,
"messages": [
{"role": "system", "content": prompt},
{"role": "user", "content": content}
]
}
api_endpoint: str = os.environ.get('OPENAI_API_ENDPOINT', 'https://api.openai.com/v1/chat/completions')
response: requests.Response = requests.post(api_endpoint, headers=headers, data=json.dumps(data))
return response.json()['choices'][0]['message']['content']
@log_execution_time
def summarize_text(text: str) -> str:
prompt: str = """
请用markdown列表格式**详细**总结我发送给你的文本。充分合理使用缩进和子列表,如果有需要可以使用多层子列表,或是在子列表中包含多个条目(3个或以上)。在每个总结项开头,用简短的词语描述该项。忽略和文章主体无关的内容(如广告)。无论原文语言为何,总是使用中文进行总结。
"""
return call_openai_api(prompt, text)
@log_execution_time
def one_sentence_summary(text: str) -> str:
prompt: str = "以下是对一篇长文的列表形式总结。请基于此输出对该文章的简短总结,长度不超过100个字。总是使用简体中文输出。"
return call_openai_api(prompt, text)
def slugify(text: str) -> str:
invalid_fs_chars: str = '/\\:*?"<>|'
return re.sub(r'[' + re.escape(invalid_fs_chars) + r'\s]+', '-', text.lower()).strip('-')
def get_summary_file_path(title: str, timestamp: int, year: Optional[str] = None, month: Optional[str] = None, in_readme_md: bool = False) -> Path:
date_str = datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d')
summary_filename: str = f"{date_str}-{slugify(title)}.md"
if year is None:
year = CURRENT_YEAR
if month is None:
month = CURRENT_MONTH
if in_readme_md:
root: Path = Path(year, month) # 更新路径为 year/month
else:
root: Path = Path(BOOKMARK_SUMMARY_REPO_NAME, year, month) # 更新路径为 year/month
return Path(root, summary_filename)
def get_text_content_path(title: str, in_summary_md: bool = False) -> Path:
text_content_filename: str = f"{CURRENT_DATE}-{slugify(title)}_raw.md"
root: Path = Path(BOOKMARK_SUMMARY_REPO_NAME, CURRENT_YEAR, CURRENT_MONTH) # 更新路径为 YEAR/MONTH
if in_summary_md:
root = Path(".")
return Path(root, text_content_filename)
def build_summary_file(title: str, url: str, summary: str, one_sentence: str) -> str:
return f"""# {title}
- URL: {url}
- Added At: {CURRENT_DATE_AND_TIME}
- [Link To Text]({get_text_content_path(title, in_summary_md=True)})
## TL;DR
{one_sentence}
## Summary
{summary}
"""
def build_summary_readme_md(summarized_bookmarks: List[SummarizedBookmark]) -> str:
initial_prefix: str = """# Bookmark Summary
读取 bookmark-collection 中的书签,使用 jina reader 获取文本内容,然后使用 LLM 总结文本。详细实现请参见 process_changes.py。需要和 bookmark-collection 中的 Github Action 一起使用。
## Summarized Bookmarks
"""
summary_list: str = ""
sorted_summarized_bookmarks = sorted(summarized_bookmarks, key=lambda bookmark: bookmark.timestamp, reverse=True)
for bookmark in sorted_summarized_bookmarks:
summary_file_path = get_summary_file_path(
title=bookmark.title,
timestamp=bookmark.timestamp,
month=bookmark.month,
in_readme_md=True
)
summary_list += f"- ({datetime.fromtimestamp(bookmark.timestamp).strftime('%Y-%m-%d')}) [{bookmark.title}]({summary_file_path})\n"
return initial_prefix + summary_list
@log_execution_time
def process_bookmark_file():
# 创建路径为 year/month 的文件夹
Path(f'{BOOKMARK_SUMMARY_REPO_NAME}/{CURRENT_YEAR}/{CURRENT_MONTH}').mkdir(parents=True, exist_ok=True)
with open(f'{BOOKMARK_COLLECTION_REPO_NAME}/README.md', 'r', encoding='utf-8') as f:
bookmark_lines: List[str] = f.readlines()
with open(f'{BOOKMARK_SUMMARY_REPO_NAME}/data.json', 'r', encoding='utf-8') as f:
summarized_bookmark_dicts = json.load(f)
summarized_bookmarks = [SummarizedBookmark(**bookmark) for bookmark in summarized_bookmark_dicts]
summarized_urls = set([bookmark.url for bookmark in summarized_bookmarks])
title: Optional[str] = None
url: Optional[str] = None
for line in bookmark_lines:
match: re.Match = re.search(r'- \[(.*?)\]\((.*?)\)', line)
if match and match.group(2) not in summarized_urls:
title, url = match.groups()
break
if title and url:
text_content: str = get_text_content(url)
summary: str = summarize_text(text_content)
one_sentence: str = one_sentence_summary(summary)
summary_file_content: str = build_summary_file(title, url, summary, one_sentence)
timestamp = int(datetime.now().timestamp())
# 保存原始文本内容
with open(get_text_content_path(title), 'w', encoding='utf-8') as f:
f.write(text_content)
# 保存总结文件
with open(get_summary_file_path(title, timestamp), 'w', encoding='utf-8') as f:
f.write(summary_file_content)
# 添加到总结书签列表
summarized_bookmarks.append(SummarizedBookmark(
year=CURRENT_YEAR,
month=CURRENT_MONTH,
title=title,
url=url,
timestamp=timestamp
))
# 更新 README 和数据文件
with open(f'{BOOKMARK_SUMMARY_REPO_NAME}/README.md', 'w', encoding='utf-8') as f:
f.write(build_summary_readme_md(summarized_bookmarks))
with open(f'{BOOKMARK_SUMMARY_REPO_NAME}/data.json', 'w', encoding='utf-8') as f:
json.dump([asdict(bookmark) for bookmark in summarized_bookmarks], f, indent=2, ensure_ascii=False)
def main():
process_bookmark_file()
if __name__ == "__main__":
main()
从GitHub书签到页面#
突然想起来了之前的clip,这两个整合到一起正好。于是进一步修改process_changes.py代码,更改文件生成的路径以符合clip,将AI总结和原文内容整合到index.html,这是现在的保存书签 - AI总结 - clip页面全流程:

全部完整代码在 bookmark-summary。AI摘要的prompt和md初始页可以再完善一下。
再次感谢 Owen’s Clip , LLM x 书签收藏:摘要 & 全文索引这两个项目的作者。