RSS订阅和本地LLM结合的初步尝试 - 流动知识检索
Jul 08, 2024 · 1737 words · 4 min · #Input #RSS #Python
AI摘要正在生成中……
书接上回:信息的保鲜期 - 流动知识的检索 | Vandee’s Blog
自从发现了omnivore之后就一直在用它做RSS订阅和after-reading,用Logseq的时候就一直在想一个能把rss订阅、PKM、LLM结合起来的workflow,中途暂停了一会就放置了很久。
虽然Logseq可以自动同步omnivore的高亮,但不好融合到workflow里。
webhook#
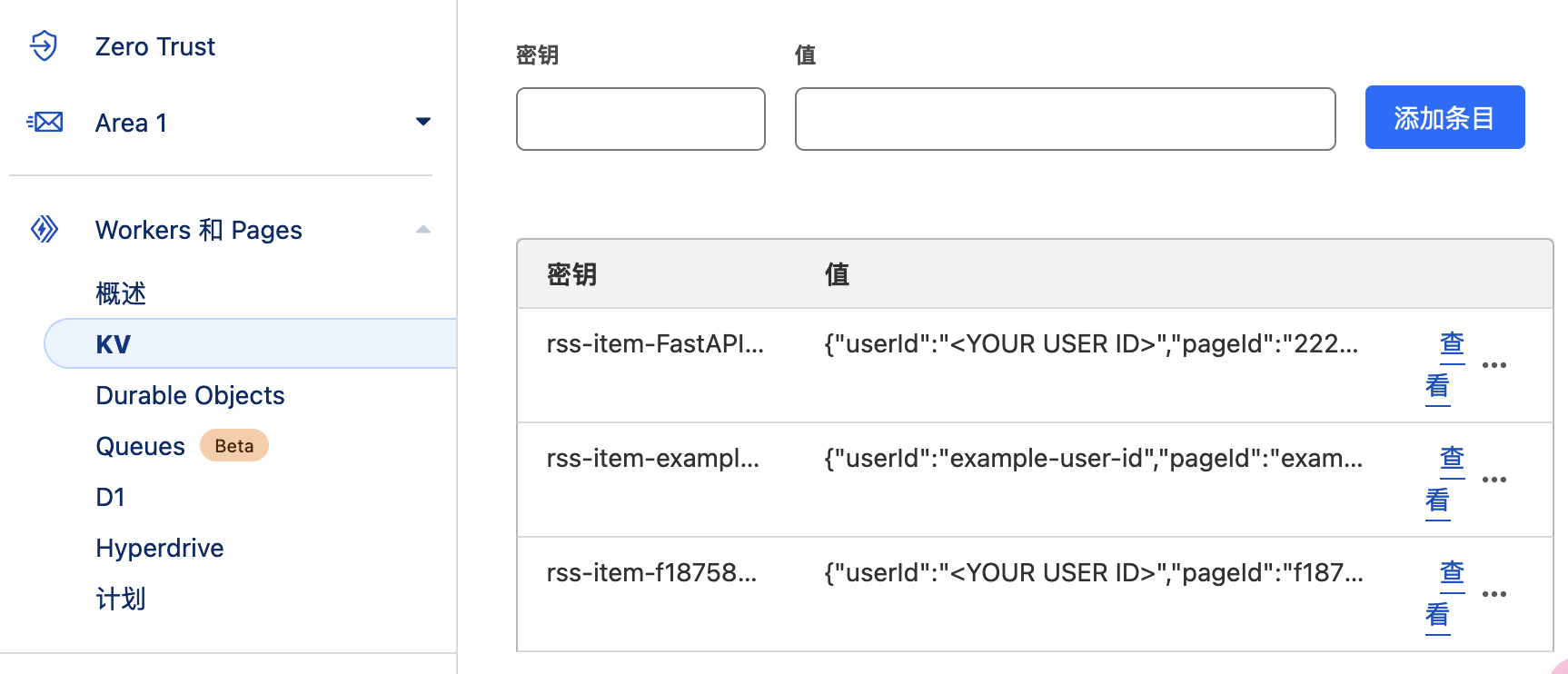
又仔细看了看omnivore的文档,发现它除了API还支持webhook,于是我在cloudflare的worker里试了一下,是可以正常处理post请求把数据储存到cloudflare的KV里的:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
if (request.method === 'POST') {
const data = await request.json()
console.log('Received data:', JSON.stringify(data))
// 提取特定的键值对
const extractedData = {
userId: data.userId,
pageId: data.page.id,
title: data.page.title,
author: data.page.author,
originalUrl: data.page.originalUrl,
highlight: data.page.highlight,
createdAt: data.page.createdAt
}
// 将提取的数据存储到 KV 命名空间
const key = `rss-item-${data.page.title}`
await omnivore.put(key, JSON.stringify(extractedData))
return new Response('Data stored successfully', { status: 200 })
} else {
return new Response('Method not allowed', { status: 405 })
}
}
但是在omnivore的webhook里设置了woker的url之后,死活不自动触发post,就先搁置了。
大佬制作了一个n8n教程:欢迎来到 n8n 中文教程 | 简单易懂的现代魔法。里面正好有一个omnivlre到Notion的实现案例:Omnivore to Notion | 简单易懂的现代魔法
Python#
然后突然想起了omnivore的Logseq插件,看了看代码,其实就是用API请求到了这些数据。
既然如此,干脆从头在Python里实现一遍。随即找到了omnivore的 OmnivoreQL: @Omnivore-app API client for Python。一翻阅读文档代码之后,有了下面的初步可行方案:
- 使用omnivore的API获取最新的文章标题、链接、高亮
- 结合ollama的本地模型(现在用的llama3)做问答
- 上传到cloudflare的KV,作为简单的数据库外部访问。n8n还玩不转。(暂时需求不大,待更新)
- RAG、LangChain待更新。
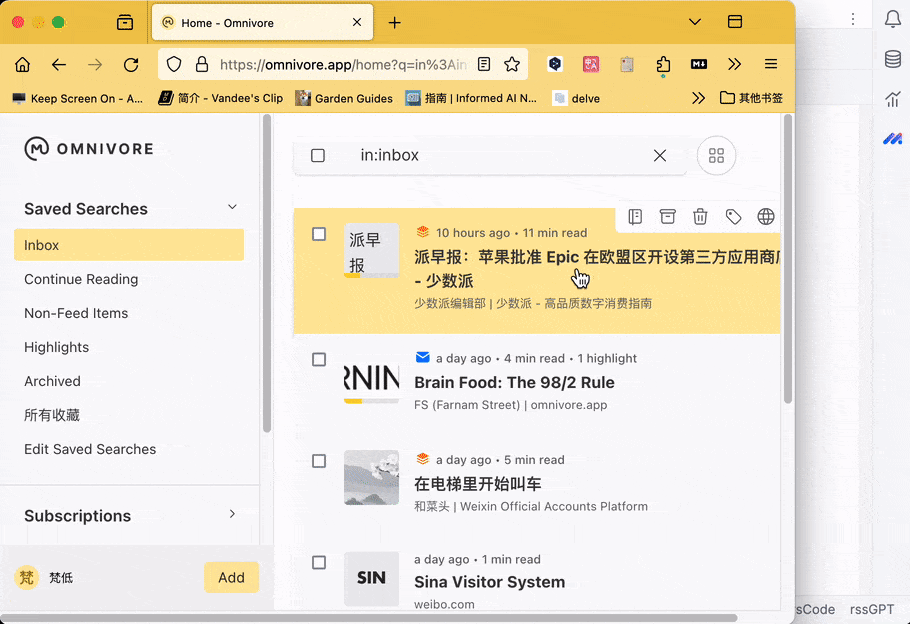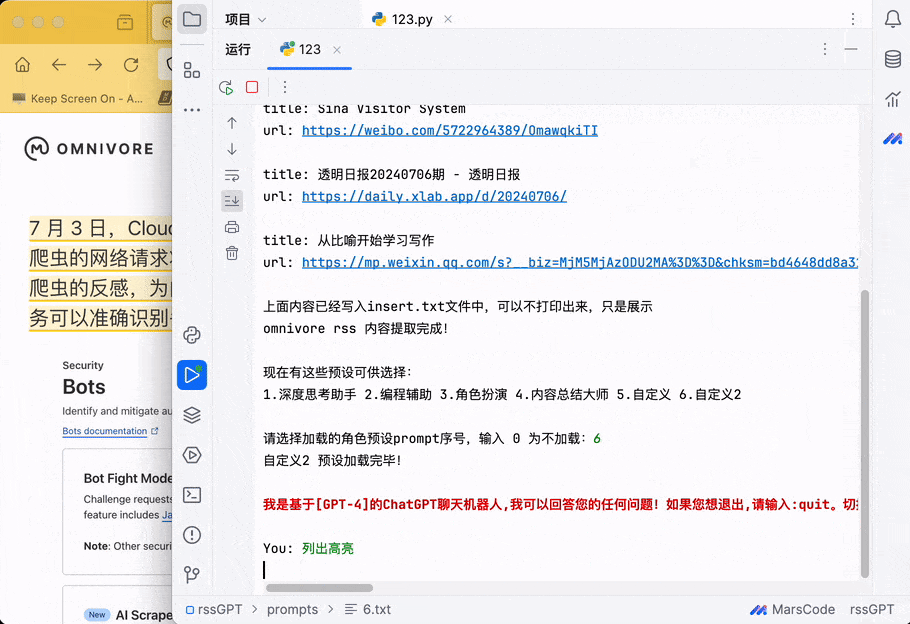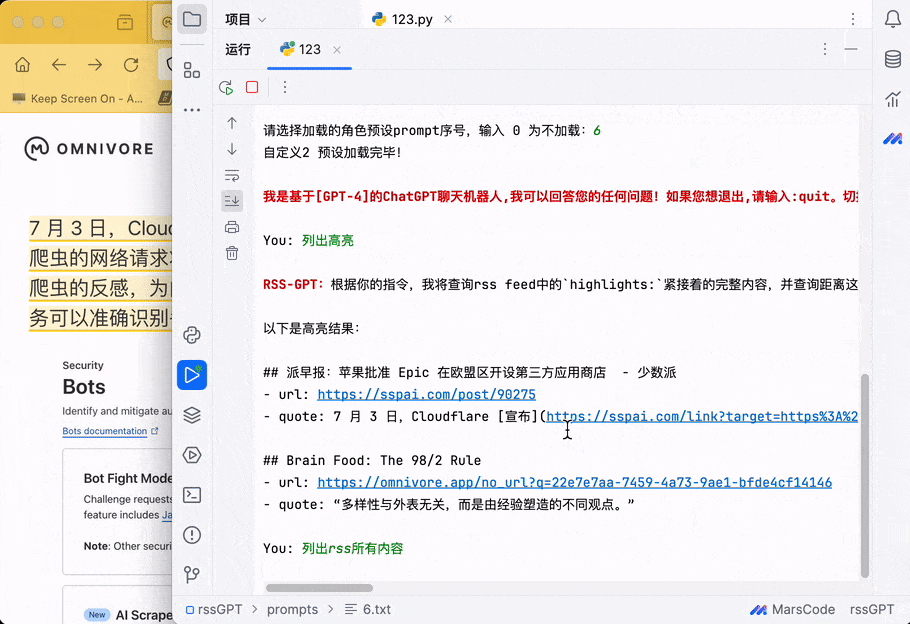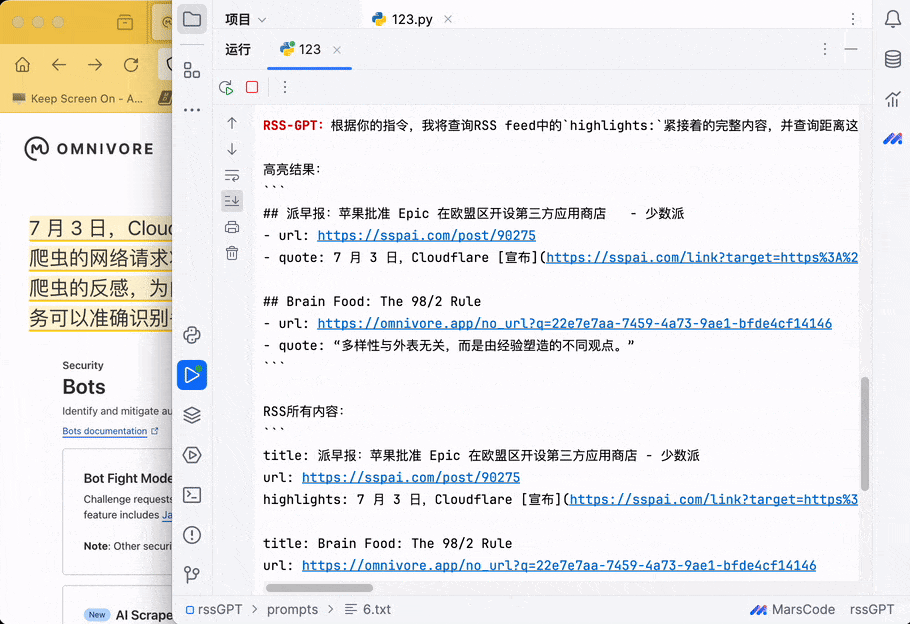
基本实现,在 omnivore 上做摘录,同步到本地文件并直接用本地 LLM 问答。当然也就可以直接在 Emacs 里实现了,暂时在 shell 里跑,后面再折腾。
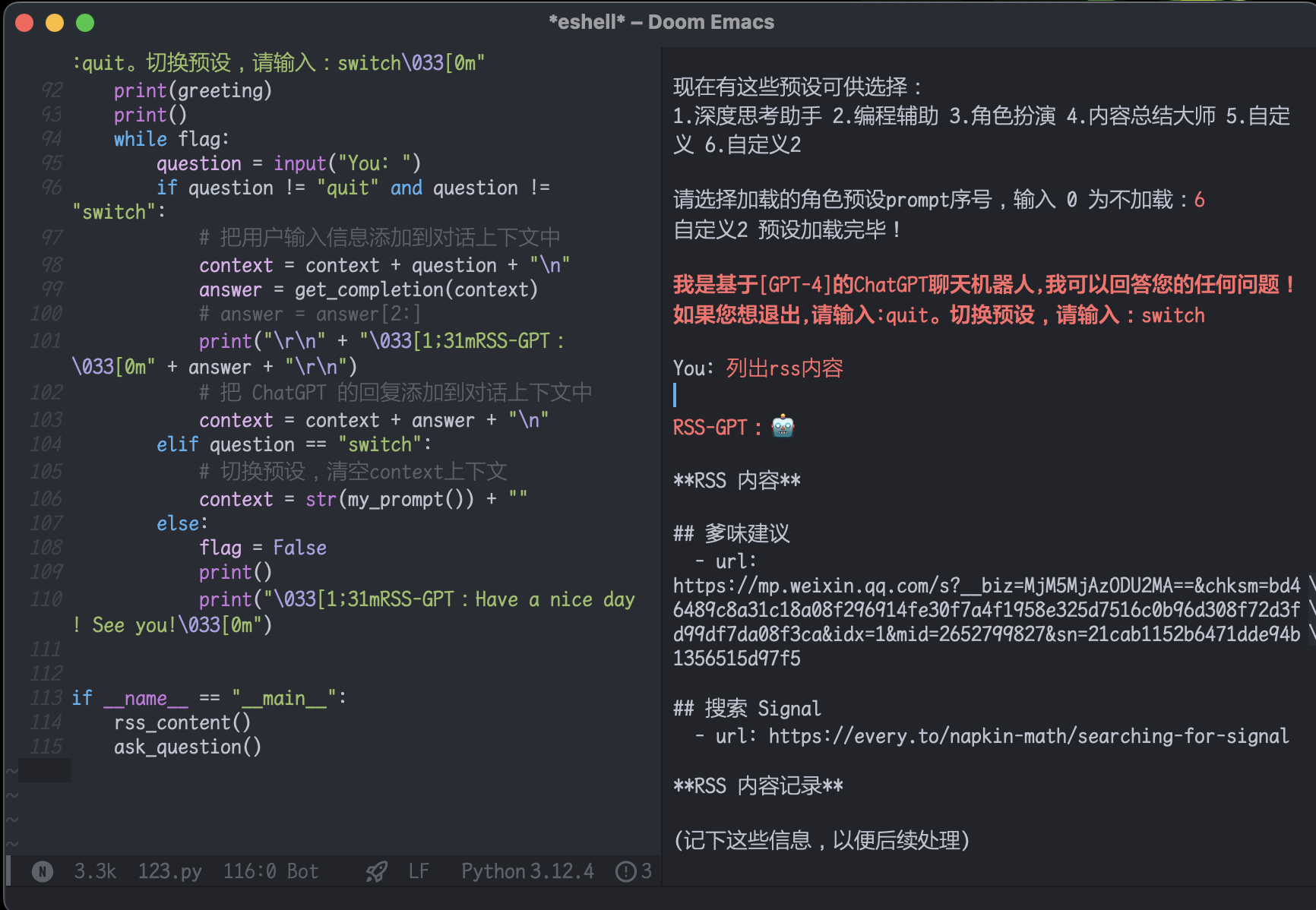
下面是完整的代码参考:
# -*- coding = utf-8 -*-
# @Project : rssGPT
# @File : 123.py
# @time : 2024-07-08
# @Author : Vandee
# @Description : 利用omnivore的API获取高亮,直接和本地LLM问答。python=3.12
import os
from omnivoreql import OmnivoreQL
import ollama
# 获取订阅内容
omnivoreql_client = OmnivoreQL("omnivore API KEY")
articles = omnivoreql_client.get_articles()
# 提取标题、链接、摘录
def rss_content():
with open('insert.txt', 'w', encoding='utf-8') as file:
for i in range(len(articles['search']['edges'])):
title = 'title: '+ articles['search']['edges'][i]['node']['title']
print(title)
file.write(title + '\n')
url = 'url: ' + articles['search']['edges'][i]['node']['url']
print(url)
file.write(url + '\n')
highlights = articles['search']['edges'][i]['node']['highlights']
for item in highlights:
quotes = 'highlights: ' + item.get('quote')
if quotes:
print(quotes)
file.write(quotes + '\n')
file.write('\r\n')
print()
file.close()
print('上面内容已经写入insert.txt文件中,可以不打印出来,只是展示')
print('omnivore rss 内容提取完成!')
print()
def get_completion(prompt, model="llama3"): # gpt-3.5-turbo-0613
messages = [{"role": "user", "content": prompt}]
response = ollama.chat(
model=model,
messages=messages,
)
return response['message']['content']
def my_prompt():
with open('insert.txt', 'r', encoding='utf-8') as i:
insert = i.read() + ''
i.close()
folder_path = './prompts/'
role_dic = {'1': '深度思考助手', '2': '编程辅助', '3': '深角色扮演', '4': '内容总结大师', '5': '自定义', '6': '自定义2'}
print('现在有这些预设可供选择:' + '\r\n' + '1.深度思考助手 ' + '2.编程辅助 ' + '3.角色扮演 ' + '4.内容总结大师 ' + '5.自定义 ' + '6.自定义2' + '\r\n')
role = input('请选择加载的角色预设prompt序号,输入 0 为不加载:')
for file_name in os.listdir(folder_path):
if file_name == role + '.txt':
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as f:
contents = f.read()
f.close()
prompt = contents + insert
print(role_dic.get(role) + ' ' + '预设加载完毕!')
print()
return prompt
else:
print('没有选择任何预设,现在是默认模式')
print()
# 提问循环
def ask_question():
context = str(my_prompt()) + ""
flag = True
greeting = '\033[1;31m我是基于[GPT-4]的ChatGPT聊天机器人,我可以回答您的任何问题!如果您想退出,请输入:quit。切换预设,请输入:switch\033[0m'
print(greeting)
print()
while flag:
question = input('You: ')
if question != 'quit' and question != 'switch':
# 把用户输入信息添加到对话上下文中
context = context + question + "\n"
answer = get_completion(context)
# answer = answer[2:]
print('\r\n'+'\033[1;31mRSS-GPT:\033[0m' + answer + '\r\n')
# 把 ChatGPT 的回复添加到对话上下文中
context = context + answer + "\n"
elif question == 'switch':
# 切换预设,清空context上下文
context = str(my_prompt()) + ""
else:
flag = False
print()
print("\033[1;31mRSS-GPT:Have a nice day ! See you!\033[0m")
if __name__ == '__main__':
rss_content()
ask_question()