PKM(个人知识管理)构建手册 - Emacs
May 22, 2024 · 17741 words · 36 min · #PKM #Org #Emacs
AI摘要正在生成中……
Intro#
For me, taking notes helps make sure that I’m really thinking hard about what’s in there. If I disagree with the book, sometimes it takes a long time to read the books because I’m writing so much in the margin. Bill Gates
对我来说,做笔记有助于确保我真正认真思考其中的内容。如果我不同意这本书,有时需要花很长时间才能读完这本书,因为我在页边空白处写了太多内容。—比尔·盖茨
这段时间关于PKM(个人知识管理)的构建起起伏伏,究其原因大概是我的思维工具跟不上思维了,工具用起来不顺手了。好在一些关键的问题都解决了,现在总结梳理成册,提供一个我个人觉得还比较靠谱,能有效的组织思维、呈现思维、扩展思维的PKM手册,也是一个模板。
从2022年开始用Notion,那个时候还不知道PKM是什么,就随心所欲的乱记一通。历经了Obsidian、Logseq,再到现在的Emacs,org-mode,通过做笔记和折腾这些笔记软件,不断深入了解这些软件的作者、笔记软件的设计理念,我觉得我的思维、认知、学习方法、写作、表达都有了质的提升。工欲善其事,必先利其器,对我而言,一个称手的笔记工具是很必须的。这个PKM方法就是我披荆斩棘的那个柳条,张三丰的太极,有形易于无形。这也就是在说,一个工具能发挥出多大效果,取决于使用者。爱因斯坦不需要记笔记,他的笔记直接就发表了🤣。对于PKM和做笔记,你可以不用,但我喜欢我有。
一个科学的,适合自己的PKM对思维的提升就好像,擎天柱组合了扩展装甲。再加上AI越来越易用,形成一些思维的语料通过LLM来拓展思维一定会是未来更有效的学习模式。而这个「PKM-base」库,就是我的扩展装甲。逐渐的,PKM这个工具和我的思维已经又融为一体,对于这个进展我很兴奋,似乎我离我的太极又近了一步。
作为思维的另一个同步的呈现,以一生来度量,这个手册也会一直更新。
对于数字笔记来说,Markdown很实用,可读性也很强,兼容性和扩展性更不用说,而Org更有个性,更符合我现在的需求,在Emacs里,想实现的个性化功能,基本上都可以使用Elisp语言自己写函数来搞定,awesome!
无思维不笔记,PKM不做本末倒置的事,让它帮助自己拓展思维,提升思维、学习、认知的效率,找到知识的缝隙,更好的认知世界、认知自我才是本质。Notion、Logseq、Obsidian、Roam Research、Heptabase,未来还会有更多的笔记软件,适合自己的才是最好的,选择一个笔记软件、笔记工具就是在选择一个生态、一个系统,下一个笔记软件,何必是笔记软件。
现在的PKM(个人知识管理)体系还有许多需要完善的地方,我也肯定还会有我的下一个笔记软件,它也一定不是一个笔记软件。
Manual#
这是一个以 Emacs 为基础编辑器、文件管理的Org-mode本地笔记PKM。
至于Emacs是什么,流传着一句话:Emacs是神的编辑器,Vim是编辑器之神。
本手册包括:
- Prerequisites:开始构建本PKM需要的工具和准备工作
- PKM:本PKM的构建原则和具体方法、org-mode的具体使用、org-capture与org-roam、Zotero、网页摘录与after-reading、中英混合输入的输入法配置与RIME
- PKM with LLM:PKM和大语言模型结合的使用、ollama、RAG(待更新)
总目录在页面最上方:Table of Contents
Prerequisites#
Start with:Git,GNU Emacs,doomemacs,Org mode for GNU Emacs,Org-roam。
开始你可能需要对Emacs、Org-mode、Git有一些了解,这些可以帮助到你:
GitHub - doomemacs/doomemacs: An Emacs framework for the stubborn martian hacker
doomemacs/docs/getting_started.org at master · doomemacs/doomemacs · GitHub
配置参考:
GitHub - purcell/emacs.d: An Emacs configuration bundle with batteries included
GitHub - MatthewZMD/.emacs.d: M-EMACS, a full-featured GNU Emacs configuration distribution
如何安装和基本的配置,上面都可以解决。如果你止步在了这里,直接放弃或许是更好的选择,或者使用obsidian、Logseq这样的Markdown笔记工具,更或者使用Logseq的org编辑模式,用Logseq来管理org文档(不推荐长期这么做),适合自己的才是最好的。
也可以参考我会一直更新的doomemacs配置。
PKM#
整体的笔记文件管理结构,还是ACCESS,可以选择不用。有文件夹和没有文件夹是两种不同的管理模式,例如ob和Logseq。这个手册里更主要的是分享我在构建PKM的过程中迭代的一些原则和方法,以供参考,形成、巩固自己的方法才是这个手册真正的目的,remember:有形易于无形。具体可以参看:§Vandee的PKM
Januarys用来记录每天的日志,作为简单明了的回顾和展开。如果你不喜欢文件夹管理,我觉得这个是很有必要的。
使用org-capture和org-roam-capture来创建,插入新的笔记和条目,在org-roam里也就是node节点。
example:
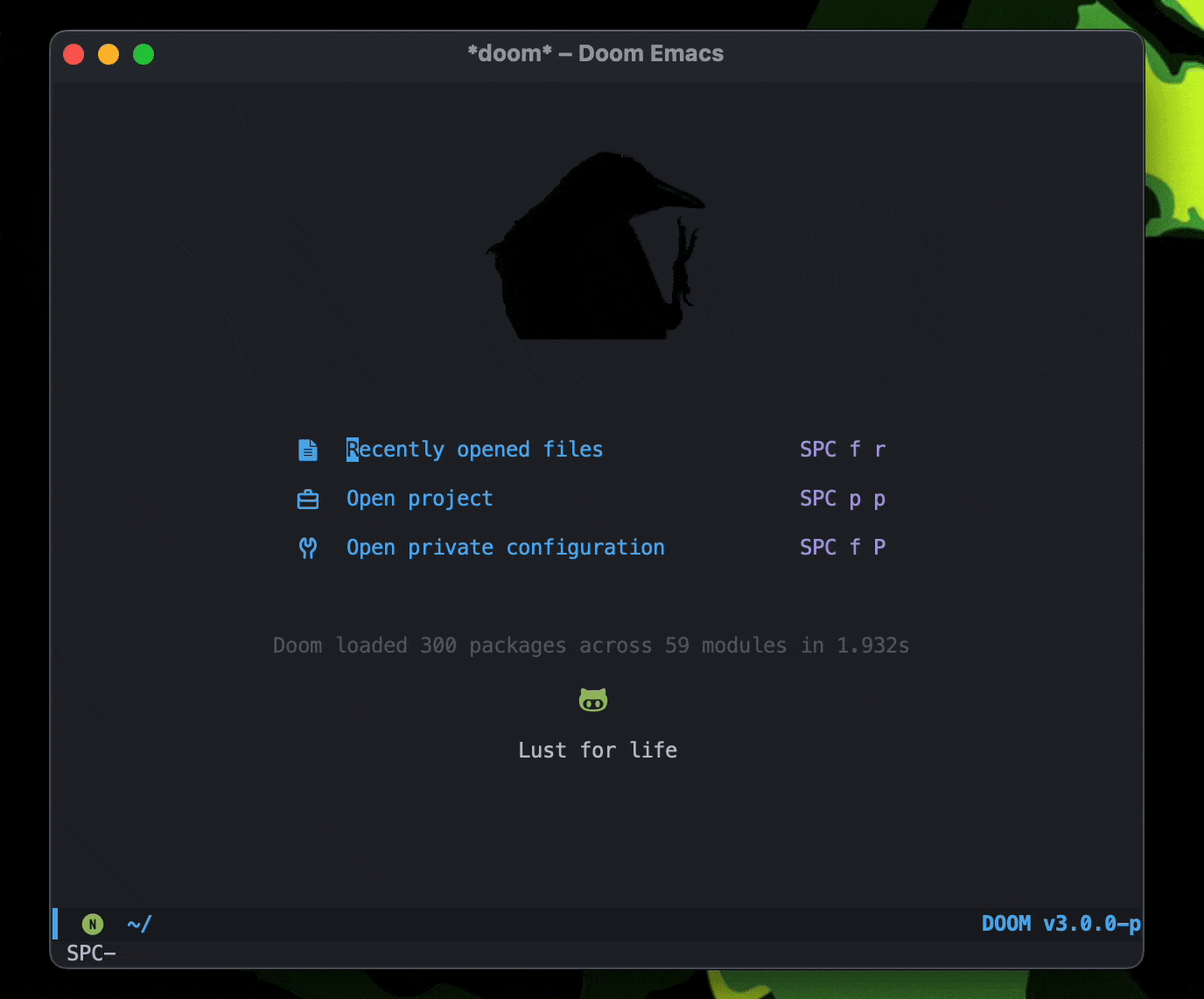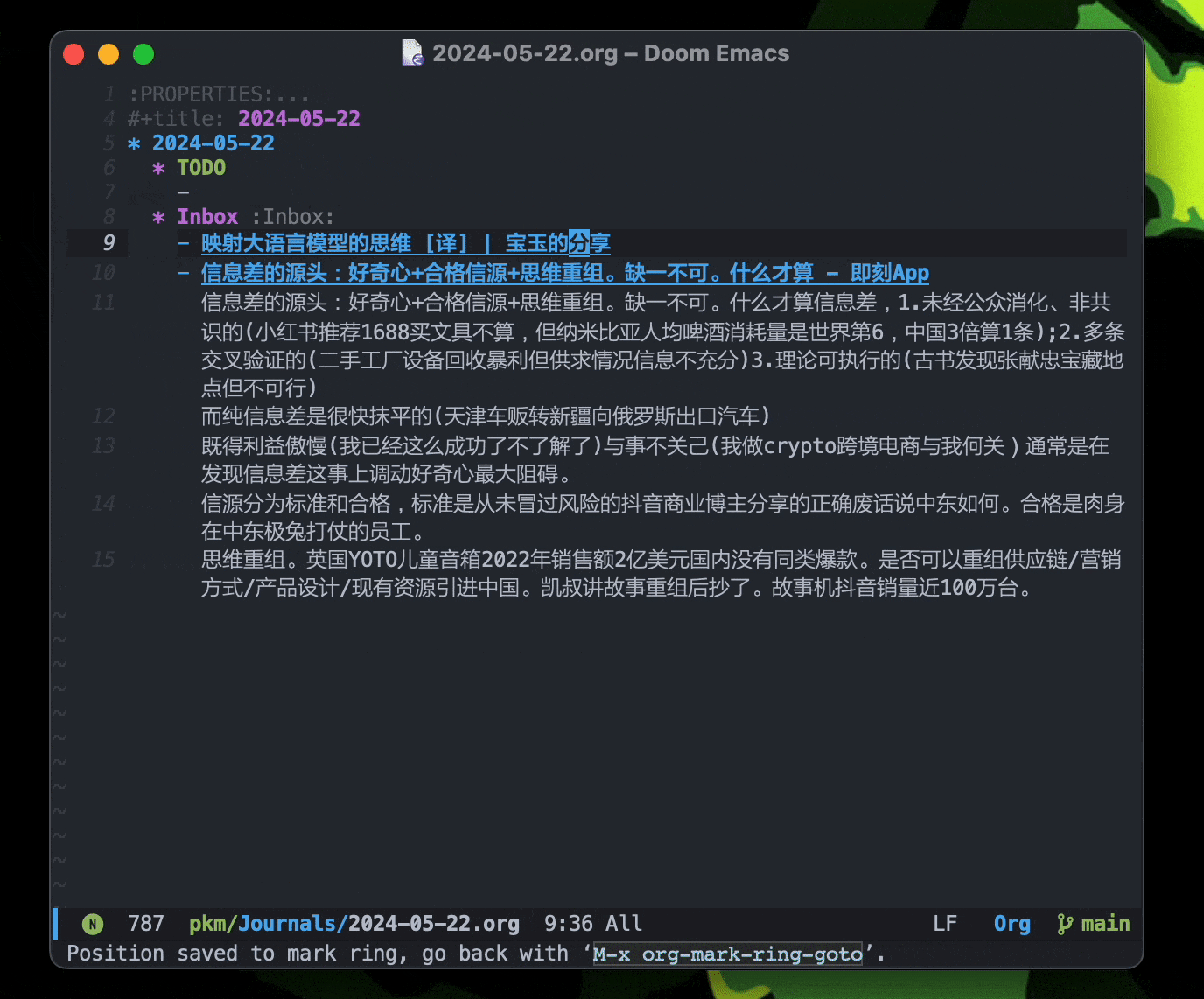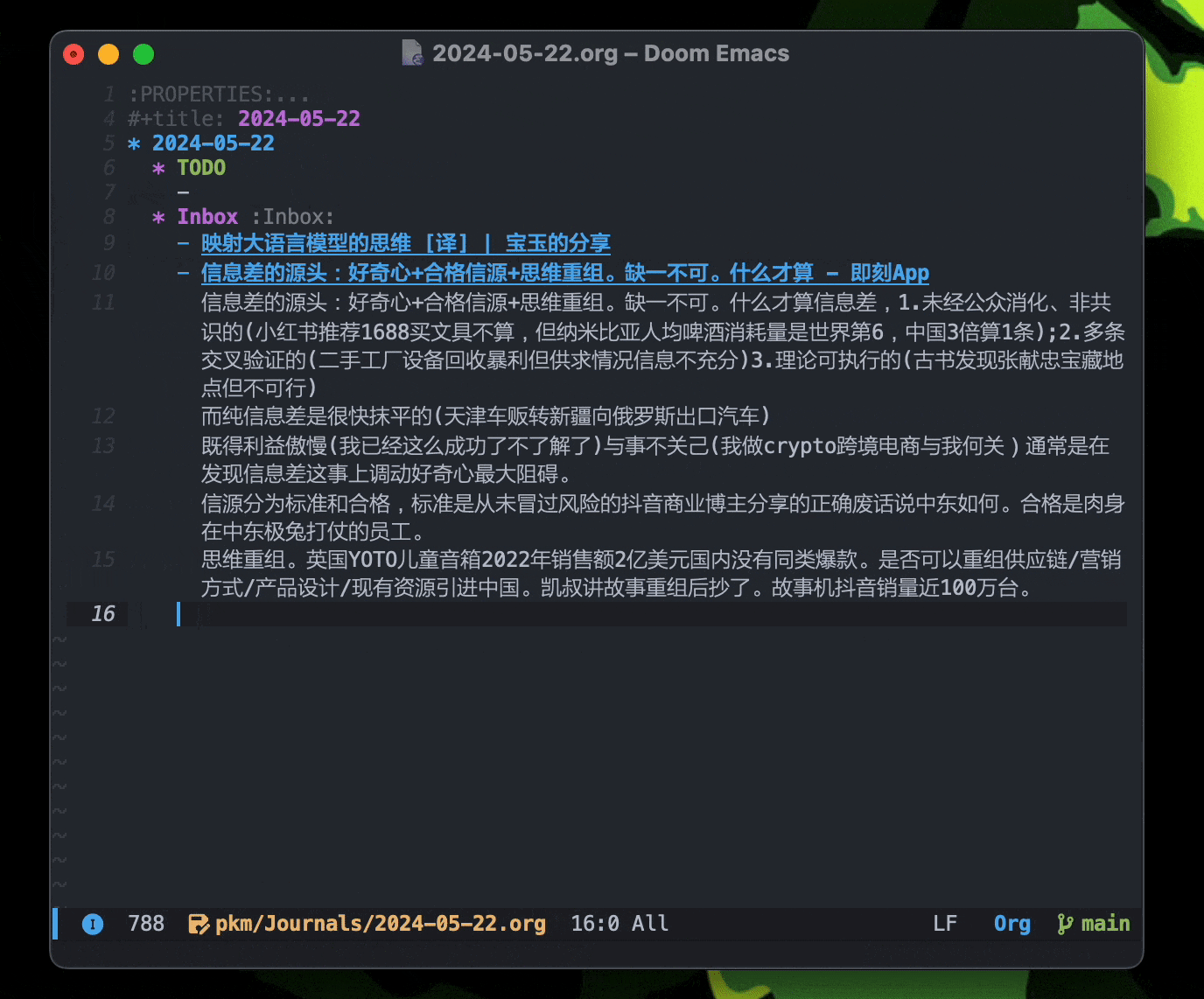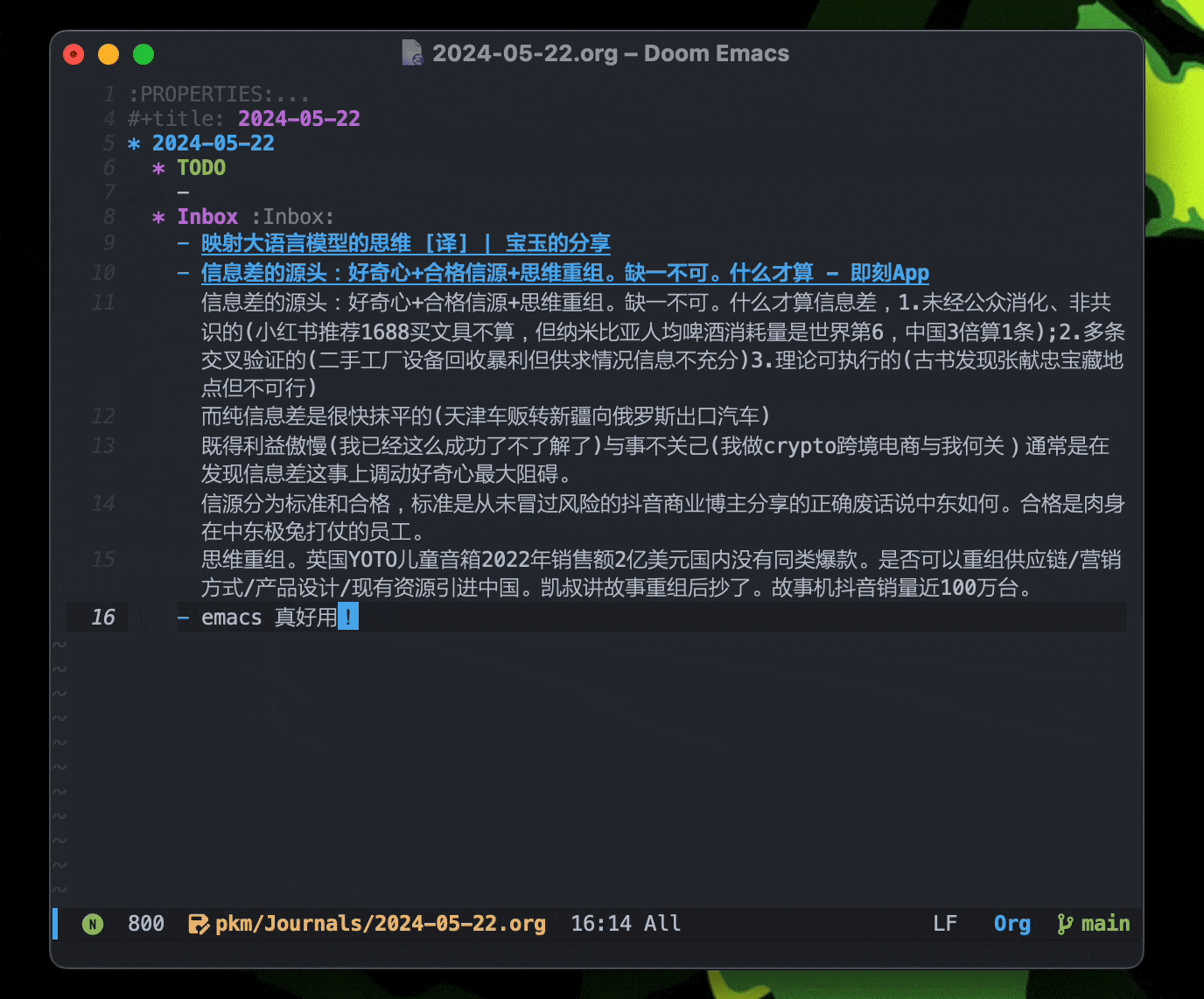
核心:原子笔记 + 双链。
你可能需要了解「原子笔记」(或者常青笔记,whatever):Evergreen notes should be atomic。
双链和反链让笔记之间的关联更加直观,当原子笔记很多的时候,反链可以直观的反应出和当前笔记相关的其他笔记。它应该同步于思维的链条。
Zettelkasten 其实并不那么重要。
Stay foolish,stay simple。
关于同步:
本地笔记没有在线笔记软件方便的地方就是多端同步与预览。我的本地笔记已经上传到了GitHub仓库,通过Git同步。临时需要修改的直接在GitHub仓库里就修改了。预览方面,我的笔记输出到了Vandee’s Digital Garden ,Vandee — Wiki
Principles#
- 一个良好的知识循环系统,应该有优秀的检索逻辑
- 笔记是思维的呈现,它应该是矢量的,当然也是原子化的
- 笔记之间的串联应该完全依靠与思维的同步
- 笔记应该让知识流动起来
- 笔记应该有优秀的层级逻辑
- 笔记的核心价值在于增援未来的自己
无思维不笔记,PKM不做本末倒置的事,让它帮助自己拓展思维,提升思维、学习、认知的效率,找到知识的缝隙,更好的认知世界、认知自我才是本质。
把人自身的思维看作一个向量,它有自己的方向和属性,在大脑里让它们串联起来的是一个个神经元和突触,在笔记里就是双链和索引。因此,要在PKM里最大程度复现大脑思维的流动,我认为,最自然的方式就是让笔记向量与思维最自然的习惯同步。
例如我们的语言系统,我们不会在用母语表达一些简单想法的时候还费力思考,笔记也应该是一样。当我大脑里现在想到一个概念,需要在笔记里找到相应的内容,脱口而出时,就应该只需要按照思维本来的习惯检索到笔记。
对于信息传播者来说,立体化的信息载体无疑可以包含更多信息的元素,对于信息接受者来说,当然理论上就可以接收到更多的信息。问题是出现在信息接收之后,也就是调动认知的这个过程。 简单来说:信息损耗率 + 认知调动率 = 新认知迭代率
Methods#
在最开始需要构建的关键体系就是检索的逻辑。
在双链部分由于原则上已经和思维高度同步,因此不需要做额外的增加思维成本的检索,只要在记录原子笔记的时候,顺其自然,高度提炼出明确、简洁的一句话概念即可。
在标签tags部分,我习惯把标签当作是一个object的二、三级属性来看待。例如《黄金时代》这本书,它的基础属性是book,我不会再重复标注它,而是写在property里,记下Type: book方便我通过函数来列举所有的书目,tag则记下文学、王小波。我习惯用单数来强调它是个属性,区别与复数的category集合的概念。
我看过许多博客和PKM,许多情况下,他们的tags在语义概念上都混用了,我习惯把tags和categories分开,分类就是分类,标签就是标签。category、property、tag还是需要在逻辑里有自然的分类,理清楚一个概念的内涵与外延。混用会导致tags越来越多,成百上千的tags反而会增加检索的成本,过个几年,大多数的tags你已经忘了当时为什么记下了,单独再去整理标签无疑是个巨大的工程,tags也失去了应当有的作用。tags的构建同样应当同步与自身的思维习惯,自身对概念、语义的记忆。
当然这也完全取决于每个人自己的习惯。
学习、获取信息和知识是在做加法,PKM里更多的应该是减法,Learn and unlearn。
可以参考我的思路:org-mode-pkm
example:Emacs,org-roam,模板创建Daily和note:
Org简介与基本语法#
Org mode 是 Emacs 的一个插件,能为 Emacs 用户提供一个强大的纯文本编辑环境,生成.org格式的文件。下面是 Org mode 官网上对自己的介绍:
Org mode is for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.
文档引言
在文件的最开始(第一个章节标题之前),你常常需要设置标题、作者以及其它导出选项。
#+title: Org 的荣光 #+author: Org 用户章节标题
由星号
*开始的行被称作章节标题(heading)。一个星号
*代表一级章节标题,两个星号**代表二级章节标题,等等。* 欢迎来到 Org ** 子章节标题 每个额外的 ~*~ 为章节的深度增加一级。简单来说,章节标题代表了一个章节的开始。然而,任何章节也可以成为一个待办事项。
待办事项是 Org 用来跟踪、整理各类的任务的基本模块。
若要把一个现有的章节标题转换为一个待办事项,仅需在其开头加上一个待办关键词,例如
TODO或者HOLD。* TODO 向世界介绍 Org ** TODO 创建一个快速开始指南链接
创建链接时把目标放在两对半角方括号中,例如:
[[目标]]。你也可以在链接里、目标之后添加描述:[[目标][描述]]。这个顺序相当好记,因为这跟 HTML 的
<a>标记<a href="目标">描述</a>一样,并且你不可能混淆不同种类的括号,因为 Org 语法里只用中括号。Org 支持一系列不同的链接目标类型,并且你还可以添加你自己的目标类型。链接目标类型由其前缀
类型:表示,例如:[[类型:目标]]。若没有提供类型,Org 会在当前文件里搜索一个符合目标的章节标题。举个例子:
[[https://orgmode.org][一个网页]] [[file:~/Pictures/dank-meme.png]] [[之前的章节标题][此文档里一个之前的章节标题]]
Ref:https://orgmode.org/zh-CN/quickstart.html、org、md和其他轻量级标记语言的用法对比表格 — GotGitHub
Org-tag#
org里的标签功能也很全面,支持多个分组,可以自动补全,还支持自定义标签的快捷键。这很好的保证了之前所说的标签的统一性,大小写或者单复数不统一会很麻烦。
在org的任意标题之后加上 :TAG1::TAG2: 就打上了标签。
进阶用法如下:
在Org Mode中,你可以通过按下快捷键来为项目或任务添加预定义的标签。以下是具体的步骤:
- 光标定位:将光标移动到你想要添加标签的项目或任务上。
- 添加标签:按下快捷键
C-c C-q,org-set-tags-command,这将打开标签过滤器。可以直接在标题的最后输入标签。在输入冒号后,M-TAG 提供了标签的自动补全和选择功能。 - 使用快捷键:在标签过滤器中,输入你为标签分配的字符常量作为快捷键。例如,如果你为
@work标签分配了字符w,那么在标签过滤器中输入w。 - 确认添加:按下
Enter键,这将为项目或任务添加相应的标签。
默认情况下,org 模式使用标准的 minibuffer 来输入标签 。然而,emacs 还提供了另外一种叫做 fast tag selection 的快速标签选择方式。在这种方式下可以仅用一个键来完成标签的选择和反选。要想使用这种方式,首先要为常使用的标签分配一个唯一字符。这个字符可以在 ‘.emacs’ 中通过配置 org-tag-alist 来设置。比如,需要在很多文件中为很多项添加 ‘:home:’ 标签。在这种情况下,可以这样设置:
(setq org-tag-alist '(("@work" . ?w) ("@home" . ? h ) ("@laptop" . ?l)))
如果标签仅仅和当前使用的文件相关,那么可以像下面这样在文件中添加 TAGS 选项:
#+TAGS: @work(w) @home(h) @tennisclub(t) laptop(l) pc(p)
标签接口会在一个 splash windows 中显示可用的标签。如果想在一个特定的标签后换行,需要在标签列表中插入一个 ‘\n’ 。
#+TAGS: @work(w) @home(h) @tennisclub(t) \n laptop(l) pc(p)
或者将他们写成两行
#+TAGS: @work(w) @home(h) @tennisclub(t)
#+TAGS: laptop(l) pc(p)
也可以像下面这样用大(花)括号手动将标签进行分组
#+TAGS: { @work(w) @home(h) @tennisclub(t) } laptop(l) pc(p)
在这种情况下,@work(w) @home(h) @tennisclub(t) 三个标签最多同时选择一个
org 也允许多个分组。当光标在这些行上的时候,不要忘了按 C-c C-c 来激活其它修改。
如果要在 org-tags-alist 中设置排它的标签组,必需要用 :startgroup 和 :endgroup 标签对,而不是用大括号。类似的,可以用 :newline 来声明一个新行。上面的例子也可以用下面的方式进行设置:
(setq org-tag-alist '((:startgroup . nil)
("@work" . ?w) ("@home" . ?h)
("@tennisclub" . ?t)
(:endgroup . nil)
("laptop" . ?l) ("pc" . ?p))
Ref:
- Tags (The Org Manual)
- emacs org mode 中的标签全参考 - 咖啡加茶 - 博客园
- 强大的 Org mode(4): 使用 capture 功能快速记录 · ZMonster’s Blog
Org-agenda#
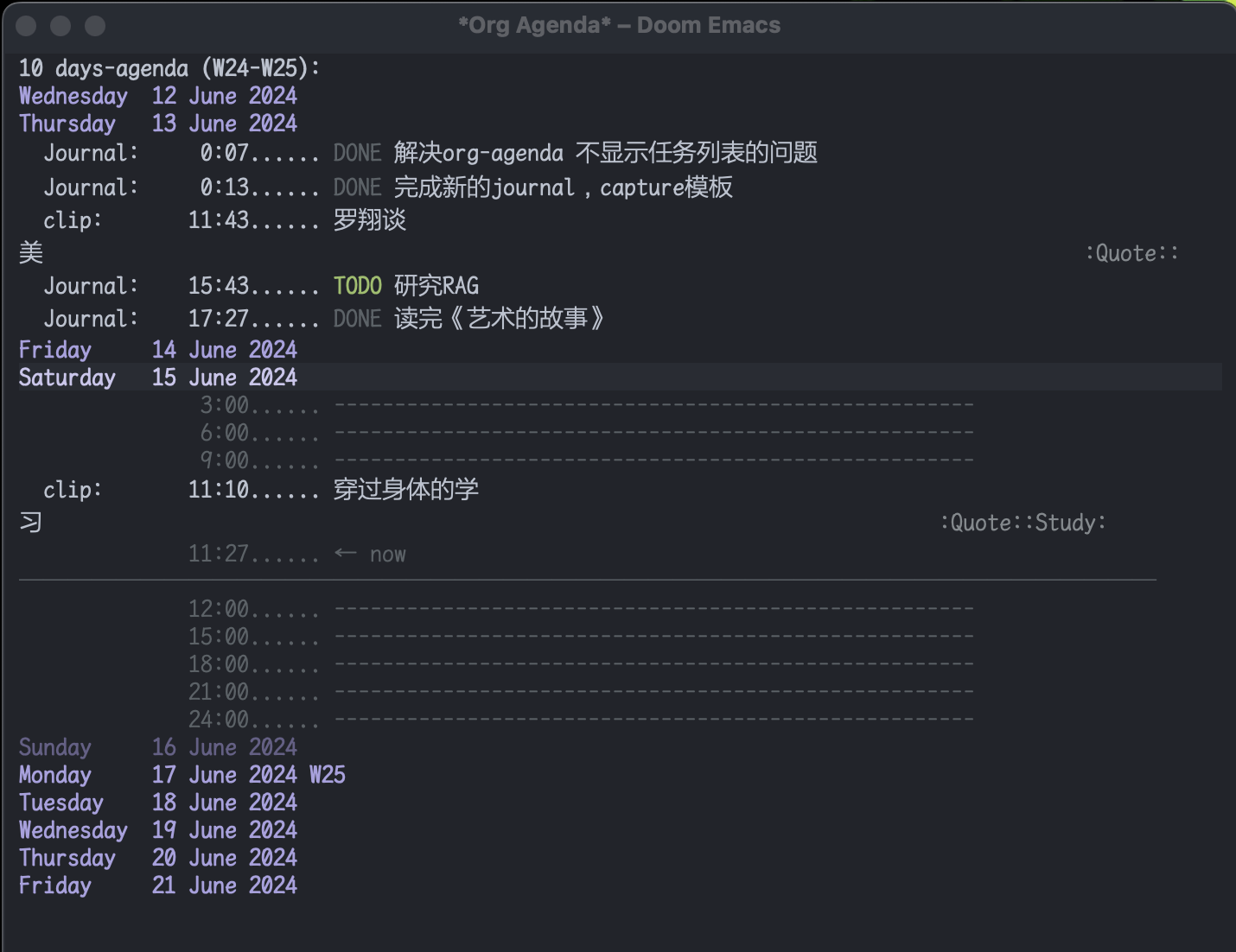
最开始是不打算用org-agenda的,因为没有太多TODO要去管理。用#TODO来标注TODO搜索也并不麻烦。但是考虑到时间久了,agenda也可以通过标注时间戳来回顾非TODO项,还是启用了。和org-roam配合,可以很清晰的回顾一个星期内重要的笔记。以后需要清除掉这些时间戳也很方便,一个正则搞定。
之前考虑到和其他笔记软件通用的问题,journal全部以单独的文件按照年份生成,现在改为集中在一个journal.org文件里。要不然以后org-agenda每次要扫描几年的journal文档会很头疼,现在改为每年一个单独的20xx-journal.org文件。
需要注意的是:在最开始设置好org-agenda要包括的文件或文件夹
;; 单独的文件
(setq org-agenda-files '("~/your/path/to/1.org" "~/your/path/to/2.org"))
;; 文件夹
;; 这样会把目录下包括子文件夹的文件都添加进去 https://emacs-china.org/t/org-txt-agenda/13506/5
(setq org-agenda-files (directory-files-recursively "~/your/directory/" "\\.org$"))
;; 文件夹但不包括子文件夹
(setq org-agenda-directory "~/your/agenda/directory/")
这是现在的样子:
TODO#
你可以通过在TODO项目下新建一个大纲树,并在子树上标记子任务来实现这个功能。为了能对已经完成的任务有个大致的了解,你可以在标题的任何地方插入
[/]或者[%]。当每个子任务的状态变化时,或者当你在标记上按 C-c C-c时,这些标记状态也会随之更新。* TODO Organize party [1/3] - [-] call people [1/2] - [ ] Peter - [X] Sarah - [X] order food - [ ] think about what music to playOrg mode 允许定义进入状态和离开状态时的额外动作,可用的动作包含两个:
- 添加笔记和状态变更信息(包括时间信息),用"@“表示
- 只添加状态变更信息,用”!“表示
这个通过定义带快速选择键的关键词时,在快速选择键后用"X/Y"来表示,X表示进入该状态时的动作,Y表示离开该状态时的动作。对于一个状态(以"DONE"为例),以下形式都是合法的:
DONE(d@) ; 进入时添加笔记 DONE(d/!) ; 离开时添加变更信息 DONE(d@/!) ; 进入时添加笔记,离开时添加变更信息除了基于 headline 的任务管理外,Org mode 还提供基于列表的任务管理,即将每个列表项作为任务,方法是在列表标记与列表项内容之间添加一个 “[ ]” 标记(注意中间包含一个字符的预留位置),这个标记在 Org mode 中被称为 checkbox 。这种任务只有三种状态(待办、进行中和完成),分别用
[ ],[-]和[X]表示。若要将用 checkbox 标记的任务标记为完成,将光标移动到对应的行,然后使用快捷键 “C-c C-c” 即可。对于包含子任务的任务,如果其子任务未全部完成,用此快捷键更改其子任务状态时,该任务的状态会自动设置为 “进行中([-])",表示子任务未全部完成;当用快捷键将所有子任务标记为完成时,它会自动更新为完成状态。
用"TODO"等关键词标记为headline为任务时,使用的快捷键同样适用于checkbox,不过略有不同:
快捷键 功能 备注 C-S-return 在当前列表项的内容后面建立一个同级列表项,标记为 “[ ]” 无列表项时不创建 M-S-return 在当前列表项后建立一个同级列表项,标记为T”[ ]” 使用
shift+← →方向键也可以快速更改TODO的状态。(setq org-todo-keywords '((sequence "TODO(t)" "DOING(i)" "|" "DONE(d@)"))) (setq org-log-done 'time) ;; 每次当你将一个项从 TODO (not-done) 状态变成任意的 DONE 状态时,那么,它就会自动在标题的下面插入一行下面的内容:CLOSED: [timestamp]
Ref:
- 新人提问,org格式中,重复任务在某一天完成后,却不能在agenda正确显示。。。 - Emacs-general - Emacs China
- Master-Emacs-From-Scratch-with-Solid-Procedures/06.Emacs-as-Agenda-by-Org
- Agenda Views (The Org Manual)
- emacsist.github.io/emacsist/orgmode/orgmode手册学习笔记.html
- 强大的 Org mode(2): 任务管理 · ZMonster’s Blog
- Org-mode 简明手册 - open source - 博客园
Org-capture#
Org-capture 是org-mode做笔记比较核心的功能,结合capture-templates可以在不离开当前buffer的情况下,快速记录、捕捉特定的内容到特定的文件和位置。加上时间戳还可以在agenda里以时间线回顾。
目前PKM里的Journal-日志、clip-剪藏、task-TODO等都是用org-capture处理的。
一定要在最开始先设置好org的默认笔记目录:(setq org-directory "~/your/path/org/")
需要注意的是:对于Doom-Emacs,需要在(after!org)里写上关于org的配置来覆盖Doom-Emacs的默认配置。
如果常规的org-capture参数不足以满足你的需求,这个函数可能对你有帮助:
;; org-capture支持自定义函数,通过function来执行
(defun my-org-goto-last-todo-headline ()
"Move point to the last headline in file matching \"* Notes\"."
(end-of-buffer)
(re-search-backward "\\* TODOs"))
(add-to-list 'org-capture-templates
'("t" "Task" entry (file+function "~/Vandee/pkm/org/Journal.org"
my-org-goto-last-todo-headline)
下面是org-capture的模板和相关配置:
(after! org
;; (server-start)
;; (require 'org-protocol)
(org-link-set-parameters "zotero" :follow
(lambda (zpath)
(browse-url
;; we get the "zotero:"-less url, so we put it back.
(format "zotero:%s" zpath))))
(setq org-agenda-files '("~/Vandee/pkm/org/Journal.org" "~/Vandee/pkm/org/clip.org"))
;; (setq org-agenda-include-diary t)
;; (setq org-agenda-diary-file "~/Vandee/pkm/org/Journal.org")
(setq org-directory "~/Vandee/pkm/org/")
(global-set-key (kbd "C-c c") 'org-capture)
;;(setq org-default-notes-file "~/Vandee/pkm/inbox.org")
(setq org-capture-templates nil)
;; (add-to-list 'org-capture-templates
;; '("j" "Journal" entry (file+datetree "~/Vandee/pkm/Journals/Journal.org")
;; "* [[file:%<%Y>/%<%Y-%m-%d>.org][%<%Y-%m-%d>]] - %^{heading} %^g\n %?\n"))
(add-to-list 'org-capture-templates
'("j" "Journal" entry (file+datetree "~/Vandee/pkm/org/Journal.org")
"* TODOs\n* Inbox\n- %?"))
(add-to-list 'org-capture-templates
'("i" "Inbox" entry (file+datetree "~/Vandee/pkm/org/Inbox.org")
"* %U - %^{heading} %^g\n %?\n"))
(defun my-org-goto-last-todo-headline ()
"Move point to the last headline in file matching \"* Notes\"."
(end-of-buffer)
(re-search-backward "\\* TODOs"))
(add-to-list 'org-capture-templates
'("t" "Task" entry (file+function "~/Vandee/pkm/org/Journal.org"
my-org-goto-last-todo-headline)
"* TODO %i%? \n%T"))
(add-to-list 'org-capture-templates '("c" "Collections"))
(add-to-list 'org-capture-templates
'("cw" "Web Collections" item
(file+headline "~/Vandee/pkm/org/websites.org" "实用")
"%?"))
(add-to-list 'org-capture-templates
'("ct" "Tool Collections" item
(file+headline "~/Vandee/pkm/org/tools.org" "实用")
"%?"))
(add-to-list 'org-capture-templates
'("cc" "Clip Collections" entry
(file+headline "~/Vandee/pkm/org/clip.org" "Clip")
"* %^{heading} %^g\n%T\nSource: %^{source}\n%?"))
Ref:
Org-roam#
Org-roam 是Emacs的一个包,也是org-mode 的扩展,可以简单的实现双链,通过org-roam-ui直观的预览。
也不是必须,只需要解决双链的查看就可以了。
org-roam也有它的capture,可以直接生成org笔记。而org-roam的「 node-insert 」可以快速在文档里直接插入新的笔记。与常规的org-mode.org文件不同的是,它可以通过带id的node「 节点 」链接来实现org-mode里的双链功能。每一个org-roam笔记都有唯一的id。
其他属性和使用基本与org-mode一致,也是生成.org文件。同样也需要配置org-roam的capture-templates。原来用org-roam创建Journal日志文件,现在已经用org-capture替代。
org-roam-ui也有和Logseq一样的网点图谱「 Graph View 」,也提供大纲结构视图,对于我来说用起来很亲切。如果你觉得org-mode可读性不强,那么org-roam-ui一定会让你喜欢。org-roam-ui是在浏览器里通过org-roam-protocol访问,需要在配置加上(require 'org-roam-protocol)。
同样也需要在最开始设置好org-roam笔记的文件夹:(setq org-roam-directory "~/your/roam/directory/")
有一个坑,org-roam会自动生成一个.orgids文件来记录生成的每个org-roam笔记的id,如果不设置会在系统根目录下自动生成。加上(org-id-locations-file "~/your/path/to/.orgids")即可。在一开始我一度认为我的电脑是不是哪里出了问题🤣,这个文件冷不丁的就冒出来了,删了重启又有了。官方文档和各大论坛里都没有这个设置,困扰了我很久,还是GPT帮我解决了。
下面是模板和相关配置:
;; (setq org-roam-dailies-directory "~/Vandee/pkm/Journals/")
(setq org-export-with-toc nil) ;;禁止生成toc
(use-package org-roam
:ensure t
:init
(setq org-roam-v2-ack t)
:custom
;; (org-roam-dailies-capture-templates
;; '(("d" "daily" plain "* %<%Y-%m-%d>\n** TODO\n- \n** Inbox\n- %?"
;; :if-new (file+head "%<%Y>/%<%Y-%m-%d>.org" "#+TITLE: %<%Y-%m-%d>\n"))))
(org-roam-directory "~/Vandee/pkm/roam/")
(org-id-locations-file "~/Vandee/pkm/roam/.orgids")
(org-roam-capture-templates
`(("n" "note" plain "%?"
:if-new (file+head "${title}.org"
"#+TITLE: ${title}\n#+UID: %<%Y%m%d%H%M%S>\n#+FILETAGS: \n#+TYPE: \n#+SOURCE: \n#+DATE: %<%Y-%m-%d>\n")
:unnarrowed t))
)
(org-roam-completion-everywhere t)
:bind (("C-c n l" . org-roam-buffer-toggle)
("C-c n f" . org-roam-node-find)
("C-c n i" . org-roam-node-insert)
("C-c n I" . org-roam-node-insert-immediate)
("C-c n c" . org-roam-capture)
;; ("C-c n j" . org-roam-dailies-capture-today)
:map org-mode-map
("C-M-i" . completion-at-point)
;; :map org-roam-dailies-map
;; ("Y" . org-roam-dailies-capture-yesterday)
;; ("T" . org-roam-dailies-capture-tomorrow))
;; :bind-keymap
;; ("C-c n d" . org-roam-dailies-map)
:config
(require 'org-roam-dailies) ;; Ensure the keymap is available
(org-roam-db-autosync-mode)
(require 'org-roam-protocol)
)
org-roam-capture模板分组
;; org-roam-capture模板分组
(setq org-roam-capture-templates
'(
("d" "default" plain (function org-roam-capture--get-point)
"%?"
:file-name "%<%Y%m%d%H%M%S>-${slug}"
:head "#+title: ${title}\n#+roam_alias:\n\n")
("g" "group")
("ga" "Group A" plain (function org-roam-capture--get-point)
"%?"
:file-name "%<%Y%m%d%H%M%S>-${slug}"
:head "#+title: ${title}\n#+roam_alias:\n\n")
("gb" "Group B" plain (function org-roam-capture--get-point)
"%?"
:file-name "%<%Y%m%d%H%M%S>-${slug}"
:head "#+title: ${title}\n#+roam_alias:\n\n")))
Ref:
- org-roam v2 的 backlinks buffer 能否显示指向当前文件的所有 headlines 的反链 - Org-mode - Emacs China
- org-roam的官方论坛:Org-roam - discourse
- https://systemcrafters.net/build-a-second-brain-in-emacs/5-org-roam-hacks/
- 使用 org-roam 构建自己的知识网络 · ZMonster’s Blog
- Boris Buliga - org-roam
- Org-roam(v2) 以及 org-roam-ui 的使用姿势(已支持Emacs 29 内置的 sqlite) - Org-mode - Emacs China
Org-export#
单独导出成MD、HTML或其他格式,Org-mode里就可以,也可以使用这些工具 。批量导出,由于每个人的排版和格式习惯不同,还是自己用自己熟悉的语言,写几个正则,搞个脚本。
;; 当前buffer下,替换markdown的链接和标题格式到org-mode的格式,排除图片的转换、替换代码块格式。
(defun my-markdown-to-org ()
(interactive)
(save-excursion
;; 转换Markdown标题为Org-mode标题
(goto-char (point-min))
(while (re-search-forward "^\s*\\(#+\\) \\(.*\\)" nil t)
(let ((level (length (match-string 1)))
(title1 (match-string 2)))
(replace-match (concat (make-string level ?*) " " title1)))))
;; 转换Markdown链接为Org-mode链接,但是跳过图片链接
(goto-char (point-min))
(while (re-search-forward "\\[\\(.*?\\)\\](\\(.*?\\))" nil t)
(let ((title (match-string 1))
(url (match-string 2)))
(unless (and (string-match "\\(jpeg\\|png\\|svg\\)" url)
(string-match "https" url))
(replace-match (format "[[%s][%s]]" url title)))))
;; 转换Markdown代码块为Org-mode代码块
(goto-char (point-min))
(while (re-search-forward "^```" nil t)
(if (looking-back "^```")
(progn
(replace-match "#+begin_src")
(re-search-forward "^```" nil t)
(if (looking-back "^```")
(replace-match "#+end_src"))))))
Markdown to org-mode:
Pandoc转换md到org会有小问题,批量转换还是悠着点。
一个改善 Markdown to Org 转换的 Pandoc Filter 脚本 - Org-mode - Emacs China
How to migrate Markdown files to Emacs org mode format - Emacs Stack Exchange
Ref:Exporting (The Org Manual)、工具 | Org mode
Org with Zotero#
书和论文的PDF文件,我现在全部放在Zotero。快速复制单个笔记到org-mode也挺简单:
通过下载这个文件到 zotero 资料目录下的 translators 文件下,将其命名为 Zotero Select Item.js ,重启 Zotero 后在编辑-> 首选项中配置便捷复制的 Item Format 为 Zotero Select Item:
这样就可以自定义复制粘贴过去的格式了。
{
"translatorID":"76a79119-3a32-453a-a0a9-c92640e3c93b",
"translatorType":2,
"label":"Zotero Select Item",
"creator":"Scott Campbell, Avram Lyon",
"target":"html",
"minVersion":"2.0",
"maxVersion":"",
"priority":200,
"inRepository":false,
"lastUpdated":"2012-07-17 22:27:00"
}
function doExport() {
var item;
while(item = Zotero.nextItem()) {
Zotero.write("zotero://select/items/");
var library_id = item.libraryID ? item.libraryID : 0;
Zotero.write(library_id+"_"+item.key);
}
}
然后在Emacs的配置文件里加上:
(org-link-set-parameters "zotero" :follow
(lambda (zpath)
(browse-url
;; we get the "zotero:"-less url, so we put it back.
(format "zotero:%s" zpath))))
Ref:
- https://hsingko.pages.dev/post/2022/07/04/zotero-and-orgmode/
- https://www.mkbehr.com/posts/a-research-workflow-with-zotero-and-org-mode/
Org-mode美化#
我觉得原生的就挺好看,可读性也还好。
- minad/org-modern: 🦄 Modern Org Style
- 想向各位道友收集一下美化 org 的配置 - Org-mode - Emacs China
- coldnew/pangu-spacing:emacs minor-mode用于在中文/日文/韩文和英文字符之间添加空格
- 大模型时代我们怎么玩Emacs:1. 中英文输入时的空格 | remacs的世界 比pangu实用。
;; 设置标题大小
(after! org
(custom-set-faces!
'(outline-1 :weight extra-bold :height 1.25)
'(outline-2 :weight bold :height 1.15)
'(outline-3 :weight bold :height 1.12)
'(outline-4 :weight semi-bold :height 1.09)
'(outline-5 :weight semi-bold :height 1.06)
'(outline-6 :weight semi-bold :height 1.03)
'(outline-8 :weight semi-bold)
'(outline-9 :weight semi-bold))
(custom-set-faces!
'(org-document-title :height 1.2)))
;;字体,设置正文大小
(setq doom-font (font-spec :family "霞鹜文楷等宽" :weight 'regular :size 14))
;; 设置行内make up,直接显示*粗体*,/斜体/,=高亮=,~代码~
(setq org-hide-emphasis-markers t)
;; 盘古,中英文混合排版美化
;;https://github.com/coldnew/pangu-spacing
(use-package pangu-spacing)
(add-hook 'org-mode-hook
'(lambda ()
(set (make-local-variable 'pangu-spacing-real-insert-separtor) t)))
Org-protocol#
Org-protocol可以在Emacs里更方便的剪藏网页内容,做after reading。也不是必须,多切换一次窗口也还好。
protocol
求助: 在网页剪藏时用org-capture模板生成独立文件名 - Org-mode - Emacs China
用org-mode做网页书签的可以进来看一下 - Org-mode - Emacs China
插入网页连接:
技巧分享:在 emacs 中获取 firefox 当前标签页并生成 org link
或利用org-roam-capture-ref: https://www.zmonster.me/2020/06/27/org-roam-introduction.html
或者使用浏览器插件:k08045kk/CopyTabTitleUrl
Firefox这个反骨仔,经常不适配各种系统。比如不支持mac的applescript。
网页摘录和after-reading#
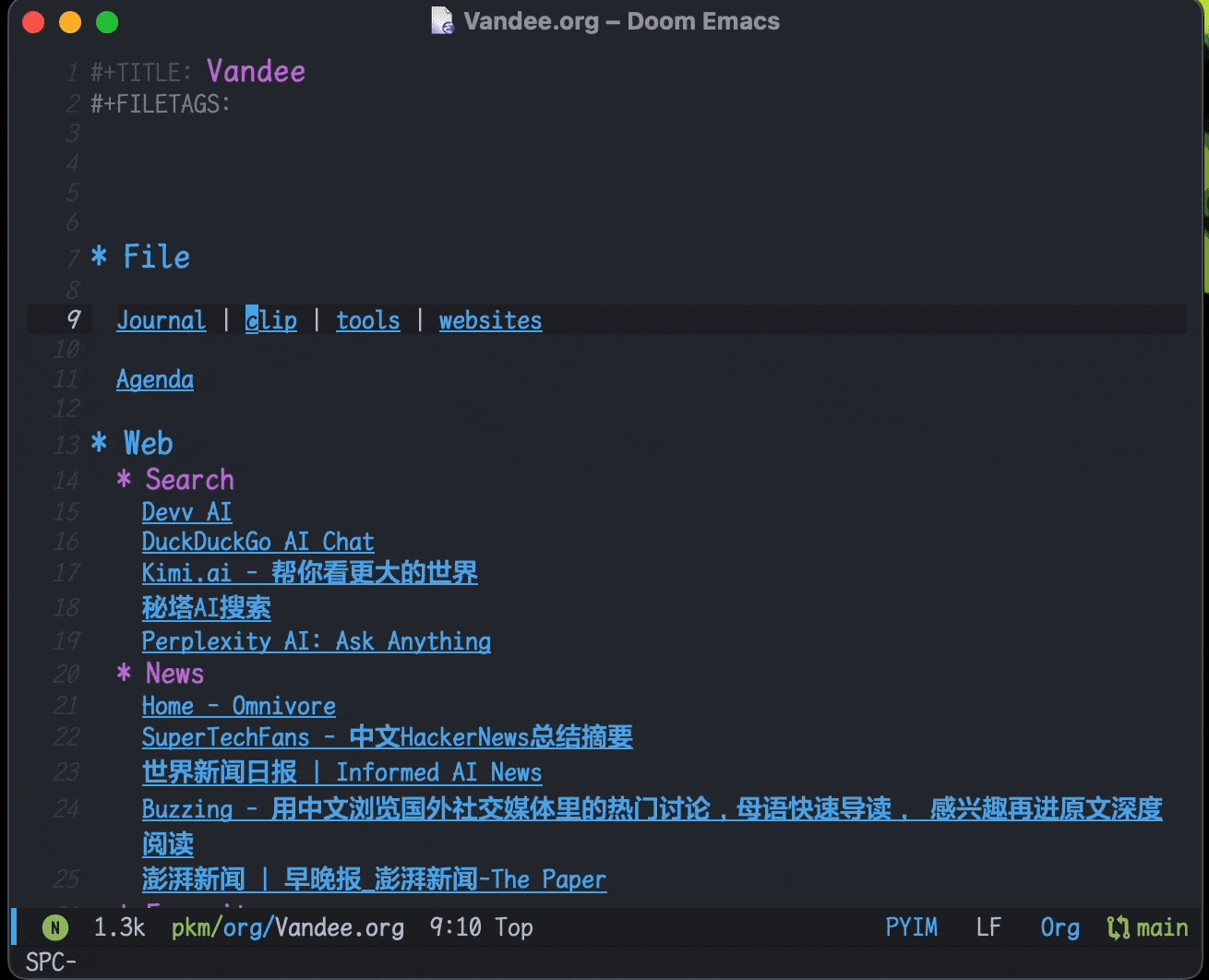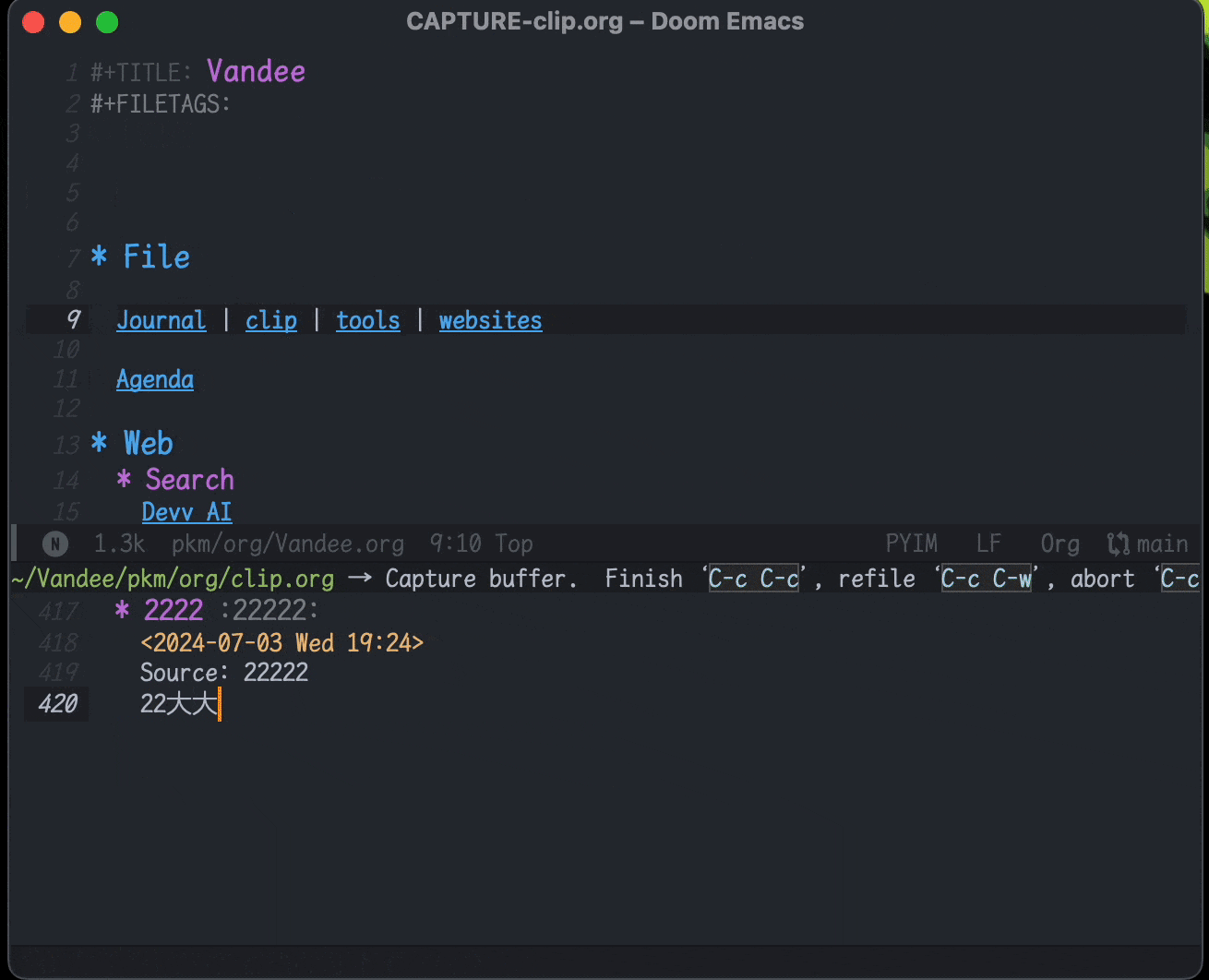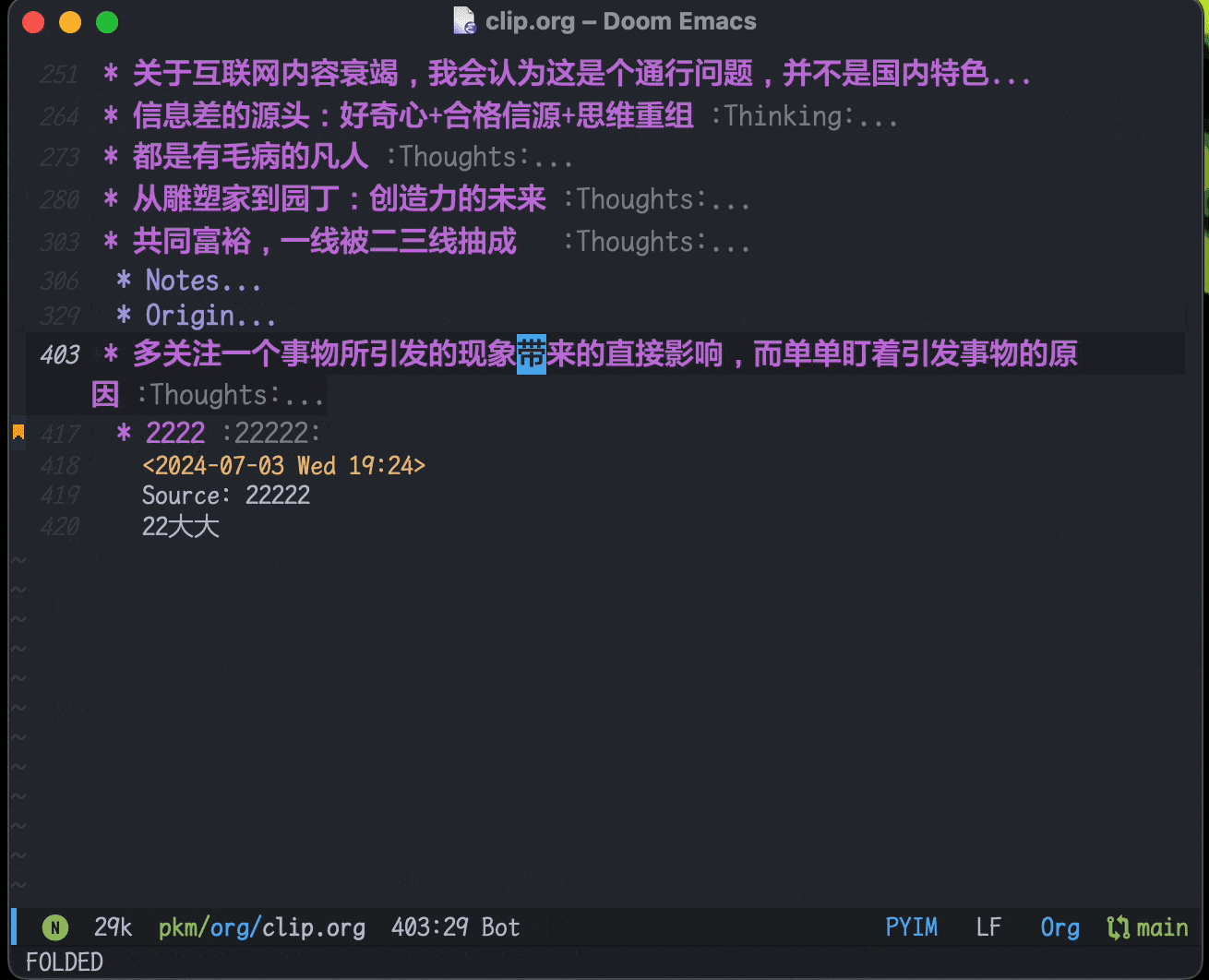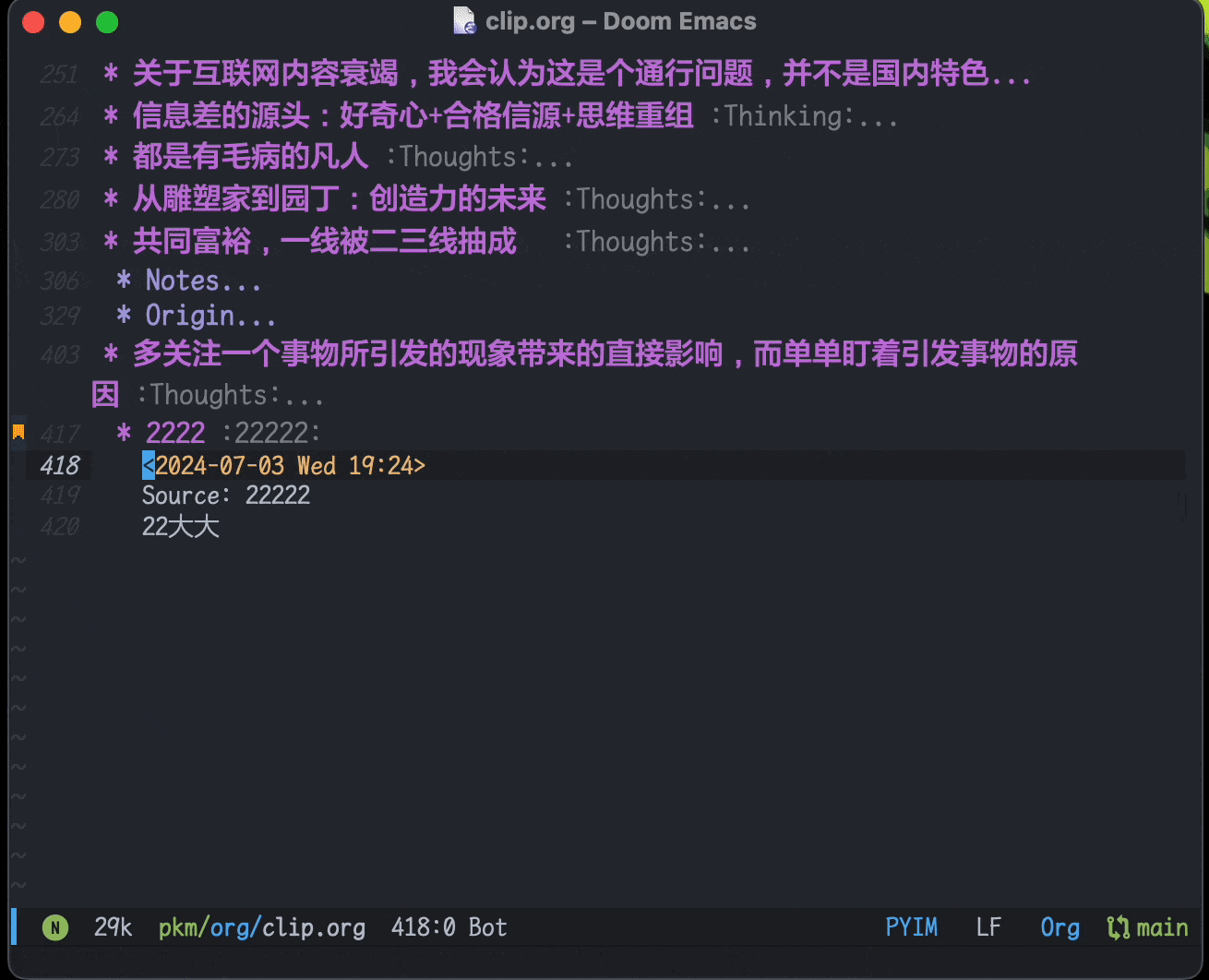
利用org-capture,做剪藏和摘录很方便。现在保存在clip.org文件里,可以在agenda里按时间线回顾,由于agenda里只有标题,也起到了类似Anki卡片回顾的作用:
有一个JavaScript我一直在用,可以选定一个网页的特定内容,在翻译和剪藏的时候挺有用,同时也微微提升了一点阅读体验。我用 DeepLX 通过沉浸式翻译如果单次翻译内容太多会报错和限制,Deepl的中文翻译还是吊打其他的。
下面的代码保存到书签,单击书签就可以了:
javascript:(function(){var e=document.body;const n=document.head.appendChild(document.createElement("style"));n.textContent=".mainonly { outline: 2px solid red; }";const t=CSS.supports("selector(:has(*))");function o(n){n instanceof HTMLElement&&(e.classList.remove("mainonly"),(e=n).classList.add("mainonly"))}function s(e){o(e.target)}function a(o){if(o.preventDefault(),t)n.textContent=":not(:has(.mainonly), .mainonly, .mainonly *) { display: none; }";else{n.textContent=":not(.mainonly *, .mainonly-ancestor) { display: none; }";var s=e;do{s.classList.add("mainonly-ancestor")}while(s=s.parentElement)}l()}function i(n){n.preventDefault(),n.deltaY<0?o(e.parentElement):o(e.firstElementChild)}function l(){document.removeEventListener("mouseover",s),document.removeEventListener("click",a),document.removeEventListener("wheel",i)}document.addEventListener("mouseover",s),document.addEventListener("click",a),document.addEventListener("wheel",i,{passive:!1}),document.addEventListener("keydown",(function o(s){if("Escape"===s.key&&(n.remove(),document.removeEventListener("keydown",o),l(),e?.classList.remove("mainonly"),!t))for(const e of document.getElementsByClassName("mainonly-ancestor"))e.classList.remove("mainonly-ancestor")}))}())
after-reading我一直用的 Omnivore,开源免费,支持RSS和Newsletter,可以自动同步高亮标注、摘录到Obsidian和Logseq。这部分用来做 流动知识的检索,文档+RAG现在的项目也越来越多了。用AI来过滤、总结这些信息流很巴适。
简单写了一个python用来直接获取高亮摘录并与本地LLM问答:RSS 订阅和本地 LLM 结合的初步尝试 - 流动知识检索 | Vandee’s Blog
有条件直接上 Readwise,配合Notion、Obsidian、Logseq都挺好用。Pocket、memos 也挺不错,可以把阅读整合到PKM里。
欢迎来到 n8n 中文教程 | 简单易懂的现代魔法这里给出了一个 omnivore 到 notion 的 workflow。
tools#
Github:https://github.com/jina-ai/reader
它可以提取网页内容并转换为markdown格式,还支持直接搜索,支持API。
Reader does two things:
- Read: It converts any URL to an LLM-friendly input with
https://r.jina.ai/https://your.url. Get improved output for your agent and RAG systems at no cost. - Search: It searches the web for a given query with
https://s.jina.ai/your+query. This allows your LLMs to access the latest world knowledge from the web.
添加下面代码到书签保存,点击书签就可以提取网页内容到markdown格式了。
javascript: var currentUrl = window.location.href;var newUrl = "https://r.jina.ai/" + currentUrl;window.open(newUrl, '_blank');window.history.pushState({}, '', currentUrl);以这个工具为跳板,就可以干许多有意思的事情了。
- Read: It converts any URL to an LLM-friendly input with
JimmyLv/BibiGPT-v1 这个项目可以自己部署,总结B站、YouTube、抖音等等的视频内容,挺好用。
u-Sir/drag-to-preview,最近发现一个Firefox浏览器插件,可以选中网页链接拖拽弹出单独的窗口预览网页,在窗口外区域鼠标点击即可关闭,很符合我的胃口。
输入法设置#
由于使用了evil,如果使用系统的输入法,每次在:w保存的时候,需要来回切换中英。推荐两种解决方案:SIS和pyim。
SIS#
emacs-smart-input-source 是一个可以自动切换输入法的Emacs包。
之前在配置SIS的时候,可能是mac系统的问题,安装macism之后,Emacs一直弹窗辅助功能设置,最近突然好了。SIS比pyim方便,不需要再内置输入法,可以直接用系统的输入法。
(use-package sis
;; :hook
;; enable the /context/ and /inline region/ mode for specific buffers
;; (((text-mode prog-mode) . sis-context-mode)
;; ((text-mode prog-mode) . sis-inline-mode))
:config
;; For MacOS
(sis-ism-lazyman-config
;; English input source may be: "ABC", "US" or another one.
;; "com.apple.keylayout.ABC"
"com.apple.keylayout.ABC"
;; Other language input source: "rime", "sogou" or another one.
;; "im.rime.inputmethod.Squirrel.Rime"
"im.rime.inputmethod.Squirrel.Hans")
;; enable the /cursor color/ mode
;; (sis-global-cursor-color-mode t)
;; enable the /respect/ mode
(sis-global-respect-mode t)
;; enable the /context/ mode for all buffers
(sis-global-context-mode t)
;; enable the /inline english/ mode for all buffers
(sis-global-inline-mode t)
)
pyim#
pyim 也可以达到相同的效果。只是这个输入法是Emacs内置的。
可能是由于我用Homebrew安装的Emacs-plus,再加上使用的doomemacs,emacs报错:编译时无法找到 emacs-module.h ,一直无法在Emacs里加载 emacs-rime 。Emacs-rime的文档里写加上(rime-emacs-module-header-root "~/emacs/include"),我试了所有的Emacs可能的路径都不行。我在Linux-Ubuntu虚拟机里,没有任何问题。
这个输入法是Emacs里内置的,如果没有指定内置的输入法,会使用系统自带的。把内置的输入法设置好,同时也解决了中英混合输入的问题,在写代码的时候,来回切换输入法太磨叽了。
不知道是什么没设置好,每次新打开一个buffer都需要重新激活pyim,暂时先加了一个org-mode的hook,在org-mode里自动激活pyim。
(add-hook 'org-mode-hook
(lambda ()
(toggle-input-method)
(setq default-input-method "pyim")))
pyim 设置:
;;输入法 https://github.com/tumashu/pyim
(global-set-key (kbd "C-\\") 'toggle-input-method)
(use-package pyim
:init
:config
(pyim-default-scheme 'xiaohe-shuangpin)
(setq default-input-method "pyim")
)
(use-package pyim-basedict
:config
(pyim-basedict-enable))
(add-hook 'org-mode-hook
(lambda ()
(toggle-input-method)
(setq default-input-method "pyim")))
;; 设置 pyim 探针
;; 设置 pyim 探针设置,这是 pyim 高级功能设置,可以实现 *无痛* 中英文切换 :-)
;; 我自己使用的中英文动态切换规则是:
;; 1. 光标只有在注释里面时,才可以输入中文。
;; 2. 光标前是汉字字符时,才能输入中文。
;; 3. 使用 M-j 快捷键,强制将光标前的拼音字符串转换为中文。
(setq-default pyim-english-input-switch-functions
'(;; pyim-probe-dynamic-english
pyim-probe-isearch-mode
;; pyim-probe-program-mode
pyim-probe-org-structure-template
pyim-probe-evil-normal-mode
))
(setq-default pyim-punctuation-half-width-functions
'(pyim-probe-punctuation-line-beginning
pyim-probe-punctuation-after-punctuation))
;; 键位绑定,解绑,转换
;; 修改默认键位映射,取消command键位
(setq mac-option-modifier 'meta)
Ref:
RIME#
如果说PKM是纸,那么输入法就是笔。
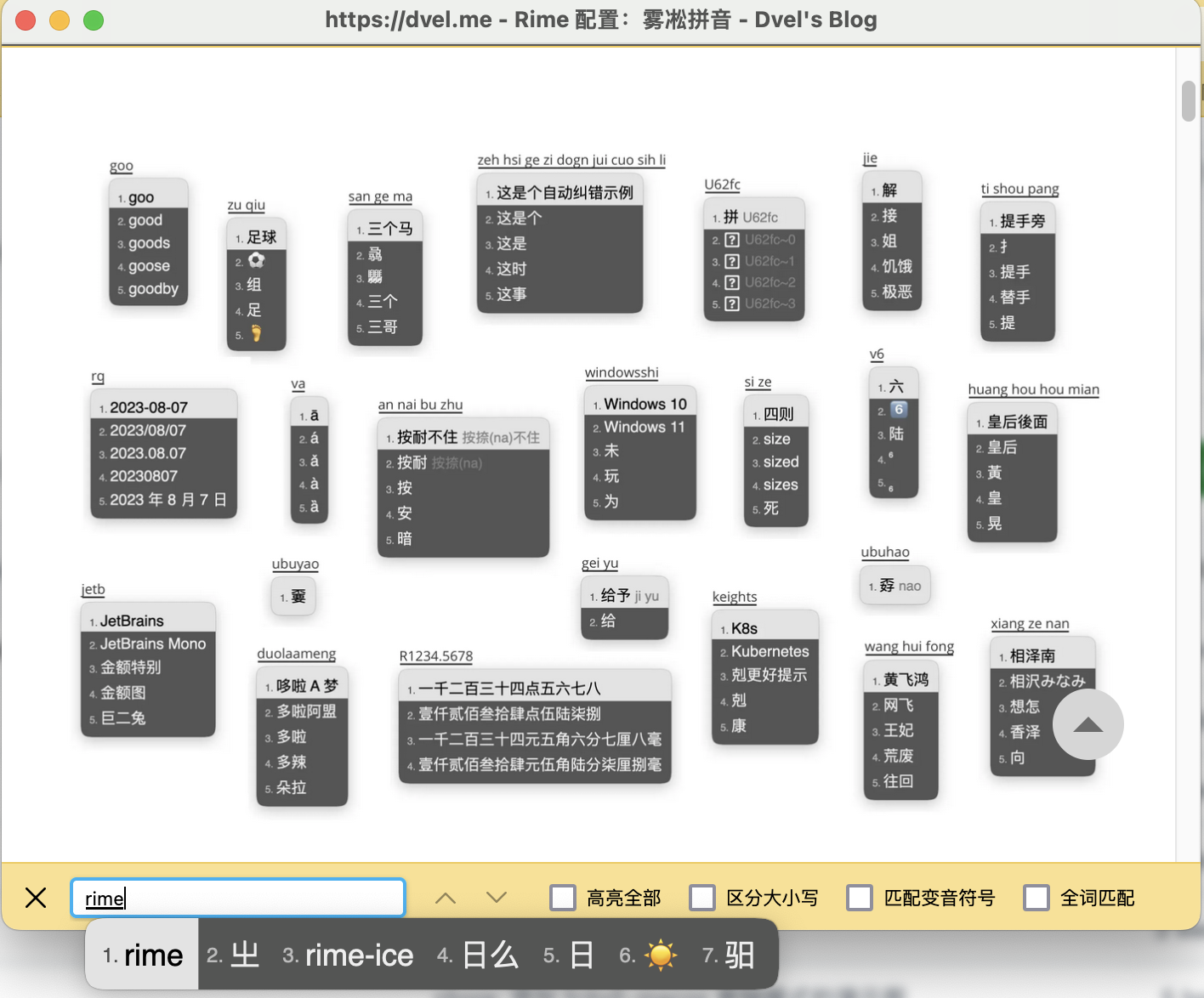
再次强烈推荐 RIME | 中州韻輸入法引擎,配合 iDvel/rime-ice: Rime 配置:雾凇拼音 | 长期维护的简体词库,多平台多端同步。已经使用了几年,非常巴适,手机端也可以同步配置。
以前输入法就各种偷偷记录用户输入习惯,现在各个输入法又还要内置AI再记录一遍。本地配置、不需要联网的输入法是我的刚需,更何况,rime还可以自挂词库。
一个巨坑,最近的RIME更新在Release 1.0.0 · rime/squirrel版本里改变了候选词横向和竖向的设置:
style/horizontal 將徹底移除,雖然本版程序仍支持,但會被新控件的默認值覆蓋
請使用 candidate_list_layout: stacked/linear 和 text_orientation: horizontal/vertical
而且最好直接在输入法外观的配置文件里,修改输入法外观的配置,而不是通用配置,反正我在通用设置里不起作用。
下面是简单的安装步骤:
;; mac:
;; mac rime: https://rime.im/download/
Homebrew: brew install --cask squirrel
或者直接下载
;; mac rime-ice
使用东风破 plum 安装: https://github.com/rime/plum
curl -fsSL https://raw.githubusercontent.com/rime/plum/master/rime-install | bash
安装 rime-ice:
℞ 安装或更新全部文件
bash rime-install iDvel/rime-ice:others/recipes/full
℞ 安装或更新所有词库文件(包含下面三个)
bash rime-install iDvel/rime-ice:others/recipes/all_dicts
℞ 安装或更新拼音词库文件( cn_dicts/ 目录内所有文件)
bash rime-install iDvel/rime-ice:others/recipes/cn_dicts
℞ 安装或更新英文词库文件( en_dicts/ 目录内所有文件)
bash rime-install iDvel/rime-ice:others/recipes/en_dicts
℞ 安装或更新 opencc ( opencc/ 目录内所有文件)
bash rime-install iDvel/rime-ice:others/recipes/opencc
;;或使用 rime-auto-deploy:https://github.com/Mark24Code/rime-auto-deploy,这个和plum只用选一个。
=======================================================
;;Linux
ibus:
https://github.com/rime/home/wiki/RimeWithIBus
sudo apt-get install ibus-rime #ibus
fcitx5:
sudo pacman -Sy fcitx5-rime # Arch Linux
sudo apt update && sudo apt install fcitx5-rime # Ubuntu / Debian / Deepin
sudo zypper install fcitx5-rime # OpenSUSE
sudo dnf install fcitx5-rime # Fedora
plum and rime-ice:
git clone --depth 1 https://github.com/rime/plum ~/plum
# 切换到东风破的目录
cd ~/plum
# 如果你使用Fcitx5,你需要加入参数,让东风破把配置文件写到正确的位置
rime_frontend=fcitx5-rime bash rime-install iDvel/rime-ice:others/recipes/full
# 如果你是用IBus,则不需加参数,因为东风破默认是为IBus版的RIME打造。
bash rime-install iDvel/rime-ice:others/recipes/full
其他可以参考下面的文章:
Tips#
这里是我遇到的一些问题和解决的办法,可能会帮助到你:
Emacs和Vim研究 | Vandee’s Digital Garden
org去除选定文字里的多余空格
;;visual 模式下选定文字英文输入 :s/ //gRef:https://panscook.com/?p=59
org导出
(setq org-export-with-toc nil) ;;禁止导出生成toc (org-roam-completion-everywhere t) ;;开启completion参考:
org-roam侧窗口
;; For users that prefer using a side-window for the org-roam buffer, the following example configuration should provide a good starting point:对于喜欢使用侧窗口作为 org-roam 缓冲区的用户,以下示例配置应该提供一个很好的起点: (add-to-list 'display-buffer-alist '("\\*org-roam\\*" (display-buffer-in-side-window) (side . right) (slot . 0) (window-width . 0.33) (window-parameters . ((no-other-window . t) (no-delete-other-windows . t)))))org-roam插入node之后,不会跳转到node而保持在原buffer
;; Bind this to C-c n I (defun org-roam-node-insert-immediate (arg &rest args) (interactive "P") (let ((args (cons arg args)) (org-roam-capture-templates (list (append (car org-roam-capture-templates) '(:immediate-finish t))))) (apply #'org-roam-node-insert args)))参考:https://systemcrafters.net/build-a-second-brain-in-emacs/5-org-roam-hacks/
反链
参考:https://emacs-china.org/t/org-roam-v2-backlinks-buffer-headlines/23368/3
设置自动显示图片,和图片显示大小
;; https://emacs-china.org/t/org-display-inline-images/25886/4 ;; https://github.com/lujun9972/emacs-document/blob/master/org-mode/%E8%AE%BE%E7%BD%AEOrg%E4%B8%AD%E5%9B%BE%E7%89%87%E6%98%BE%E7%A4%BA%E7%9A%84%E5%B0%BA%E5%AF%B8.org ;; (setq org-image-actual-width '(400)) 要在(org-toggle-inline-images)命令之前 ;; 或者在文档开头加上 #+ATTR_ORG: :width 600 ,并设置(setq org-image-actual-width nil) (add-hook 'org-mode-hook (lambda () (setq org-image-actual-width '(400)) (org-toggle-inline-images) (when org-startup-with-inline-images (org-display-inline-images t))))
Others#
lijigang/100-questions-about-orgmode: It’s all about orgmode !
emacs-immersive-translate: Emacs 版本的沉浸式翻译(支持多个翻译后端) - Emacs-general - Emacs China
混用 org-ql、columnview、org-roam、org-capture、org-super-links 塑造我的笔记流程 - Org-mode - Emacs China
我想分享一下我的emacs配置和学习思路,并向大家介绍一些我觉得有用的package - Emacs-general - Emacs China
https://emacs-china.org/t/ekg-flomo/27505/12
ekg:提供一个类似obsidian里dataview的查询汇总功能
https://github.com/protesilaos/denote
denote:提供类似org-roam的双链,快速插入等功能
Emacs里的其他笔记相关使用包
caiorss/org-wiki: Wiki for Emacs org-mode built on top of Emacs org-mode.
Kungsgeten/org-brain: Org-mode wiki + concept-mapping
weirdNox/org-noter: Emacs document annotator, using Org-mode
toshism/org-super-links: Package to create links with auto backlinks
alphapapa/org-ql: A searching tool for Org-mode.
Web/Omni Search In Emacs with consult-web or Ditching the Browser’s Default Search Engine
我的 Neovim Zettelkasten:我如何使用 Vim 和 Bash 在 Markdown 中做笔记 |米沙·范登伯格 很强,之前用bash来生成md笔记的思路一下子扩展了。使用CLI来做笔记是一个很终极的方案。
PKM with LLM#
本地笔记的优势除了隐私性,再就是,数据在自己手上,就可以干很多事。把本地的笔记文档结合LLM做思维拓展,基于个人思维习惯更精确的问答。如果说有时候双链不足以串联整个思维链条,下面这些工具如虎添翼。
看到一个大佬已经用Ollama、RAG在MacBook Pro M3 Max上实现了基于obsidian的个人AI知识助手:个人本地 (Llama3 8B) LLM 使用 WhatsApp + Obsidian 数据扩展 - Byte Tank,和我的思路基本一致。
简单写了一个python用来直接获取高亮摘录并与本地LLM问答:RSS 订阅和本地 LLM 结合的初步尝试 - 流动知识检索 | Vandee’s Blog
很久之前,看到一篇文章提出了一个观点:随着和LLM互动的增多,特别是现在各种LLM平台,ChatGPT、Claude、perplexity等等,查询、回顾、汇总这些问答是一个值得注意的点。
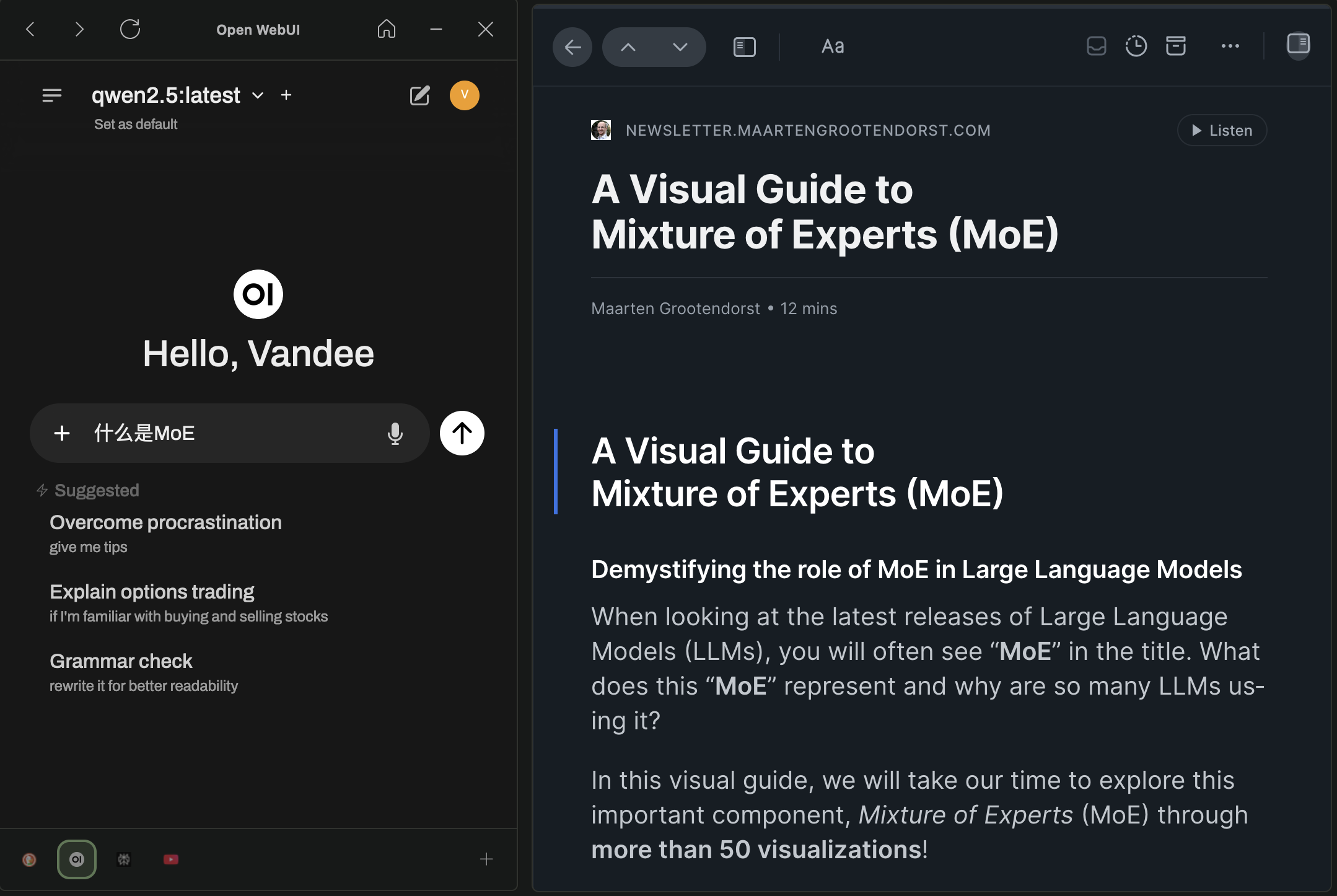
现在我的日常问答都在本地使用Open WebUI,可以导出聊天还有数据库可以直接备份,甚至还可以给对话打tag,当然也可以搜索。
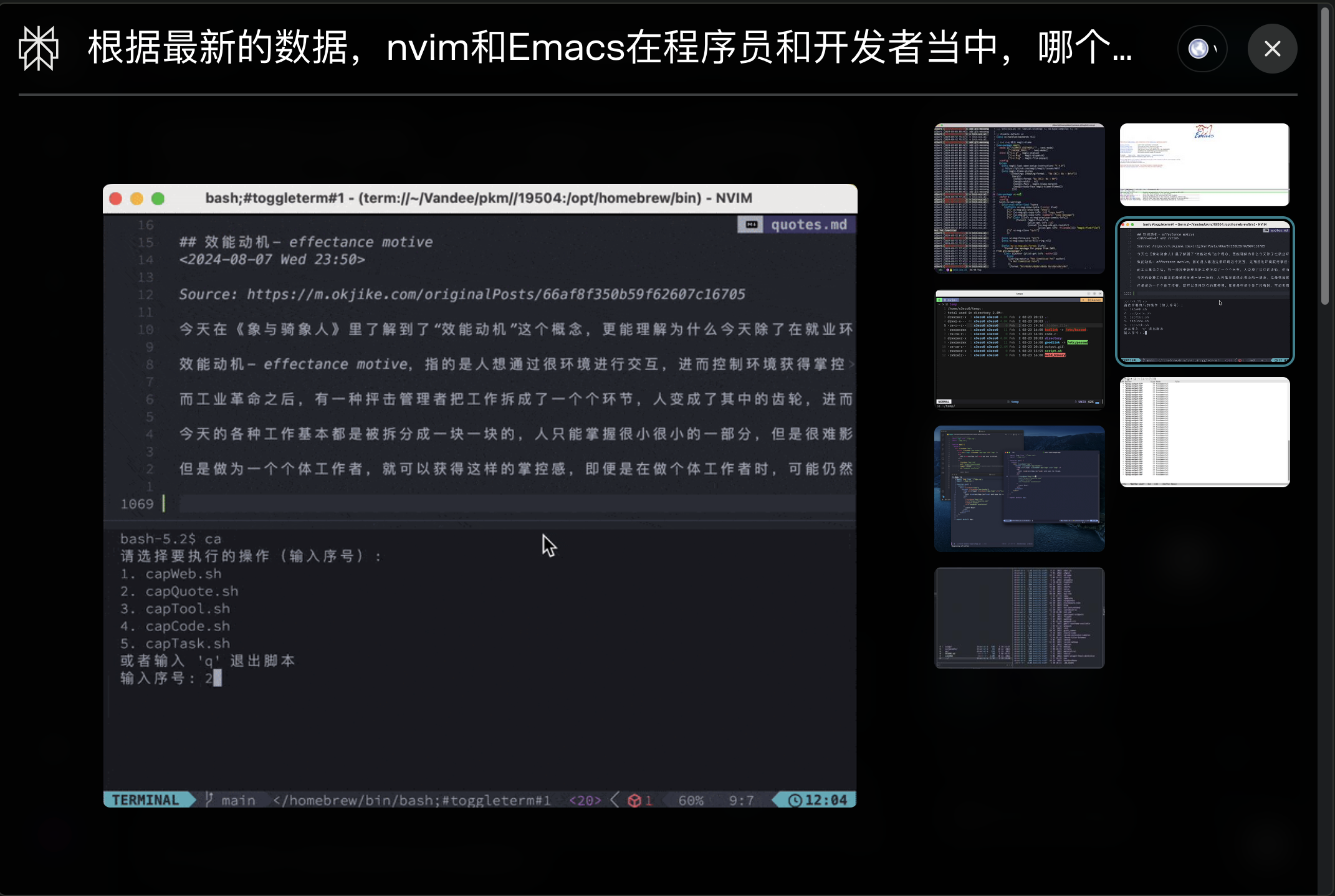
需要联网搜索的内容现在基本在perplexity了,碰巧的是,最近搜索到了自己博客的内容🤣,纪念一下:
工具推荐#
Ollama#
Ollama 可以本地部署大语言模型,目前GitHub 69.1k star,一直在用。obsidian,Emacs,Logseq都支持。如果说Cloudflare是赛博活菩萨,那ollama就是LLM筋斗云。
$ ollama serve 即可后台启动ollama服务。
docker 部署:
# Docker Pull Command docker pull ollama/ollama # CPU only docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama # AMD GPU # To run Ollama using Docker with AMD GPUs, use the rocm tag and the following command: docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm # Run model locally # Now you can run a model: docker exec -it ollama ollama run llama3 # 有时候 Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,需要将 Ollama 服务暴露给网络。 # 在Mac上设置环境变量 # 如果 Ollama 作为 macOS 应用程序运行,则应使用以下命令设置环境变量launchctl: # 通过调用launchctl setenv设置环境变量: launchctl setenv OLLAMA_HOST "0.0.0.0" # 重启Ollama应用程序。 # 如果以上步骤无效,可以使用以下方法: # 问题是在docker内部,你应该连接到host.docker.internal,才能访问docker的主机,所以将localhost替换为host.docker.internal服务就可以生效了: http://host.docker.internal:11434
ollama支持主流的开源模型如llama3,所有支持模型可查看:
Model library:Ollama supports a list of models available on ollama.com/library
相关文章:
Open WebUI#
Open WebUI 提供一个WebUI运行本地LLM,目前GitHub 31k star。良好的兼容ollama,聊天数据本地保存,可本地导入文档做RAG查询。
社区提供了插件和功能,质变的是:可以让本地LLM搜索web的内容。
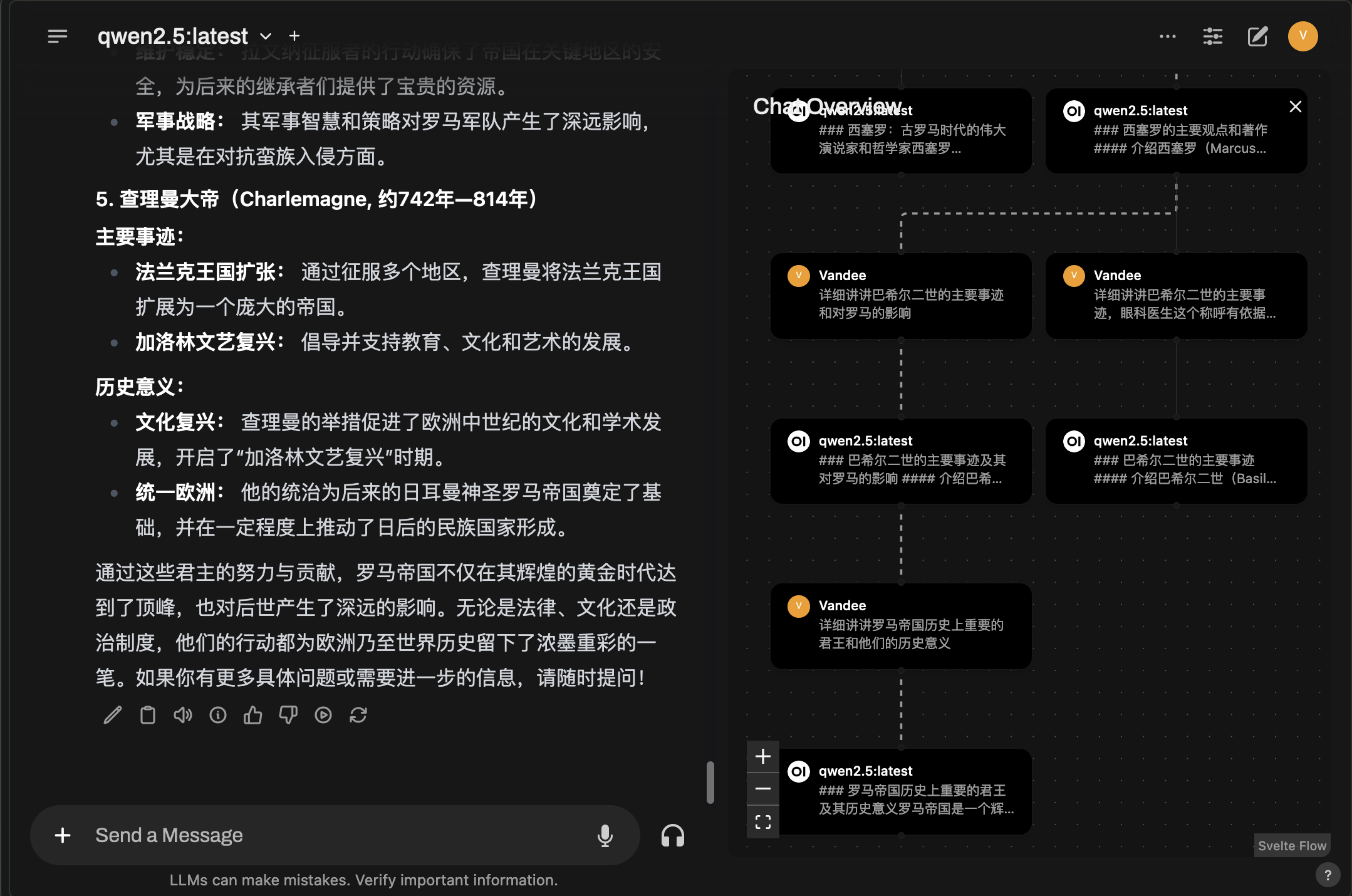
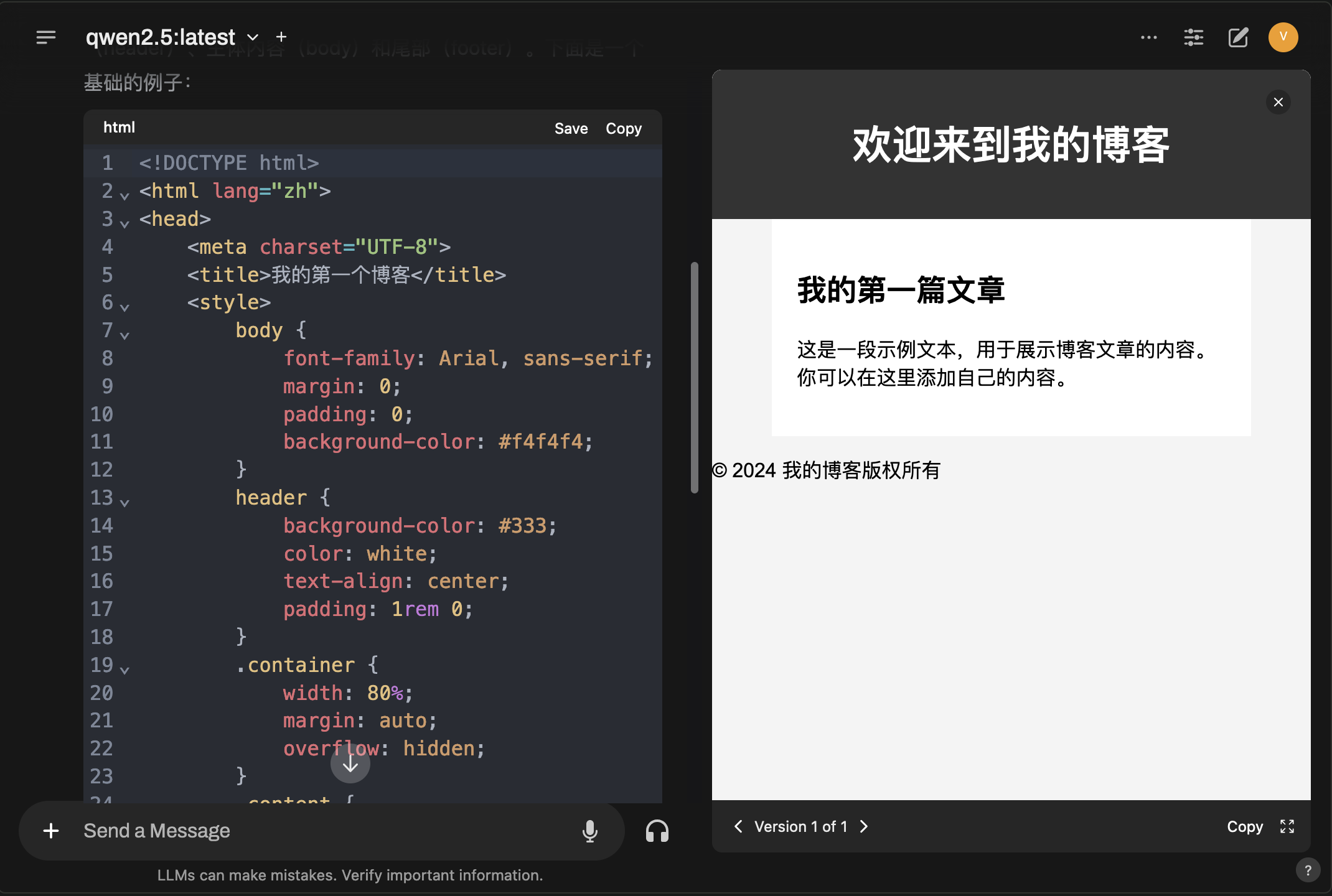
Open WebUI 在2024-10-06的版本中更新了支持类似Claude artifacts的artifacts: 🎨 Artifacts Feature: Render web content and SVGs directly in the interface, supporting quick iterations and live changes,不过只支持原生的HTML和CSS。还更新了Overview,可以在白板里展示对话的内容,太实用了,史诗级更新!
其他主要功能:
📚 本地 RAG 集成:通过突破性的检索增强生成 (RAG) 支持深入探索聊天交互的未来。此功能将文档交互无缝集成到您的聊天体验中。您可以将文档直接加载到聊天中或将文件添加到文档库中,在查询之前使用
#命令轻松访问它们。🔍 RAG 的网络搜索:使用
SearXNG、Google PSE、Brave Search、serpstack、serper、Serply、DuckDuckGo和TavilySearch并将结果直接注入您的聊天体验中。🌐 网页浏览功能:使用
#命令后跟 URL,将网站无缝集成到您的聊天体验中。此功能允许您将网络内容直接合并到您的对话中,从而增强交互的丰富性和深度。
docker部署相当简单:
CLI:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainDocker compose: https://github.com/open-webui/open-webui/blob/main/docker-compose.yaml
services: ollama: volumes: - ollama:/root/.ollama container_name: ollama pull_policy: always tty: true restart: unless-stopped image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest} open-webui: build: context: . args: OLLAMA_BASE_URL: '/ollama' dockerfile: Dockerfile image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main} container_name: open-webui volumes: - open-webui:/app/backend/data depends_on: - ollama ports: - ${OPEN_WEBUI_PORT-3000}:8080 environment: - 'OLLAMA_BASE_URL=http://ollama:11434' - 'WEBUI_SECRET_KEY=' extra_hosts: - host.docker.internal:host-gateway restart: unless-stopped volumes: ollama: {} open-webui: {}# Manual Update 手动更新 # Pull the Latest Docker Image: 拉取最新的 Docker 镜像: docker pull ghcr.io/open-webui/open-webui:main # Stop and Remove the Existing Container: 停止并删除现有容器: This step ensures that you can create a new container from the updated image. 此步骤确保您可以从更新的映像创建新容器。 docker stop open-webui docker rm open-webui # Create a New Container with the Updated Image: 使用更新后的映像创建一个新容器: Use the same docker run command you used initially to create the container, ensuring all your configurations remain the same. 使用最初用于创建容器的相同 docker run 命令,确保所有配置保持不变。 docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main This process updates your Open WebUI container to the latest version while preserving your data stored in Docker volumes. 此过程将您的 Open WebUI 容器更新到最新版本,同时保留存储在 Docker 卷中的数据。 # Updating Docker Compose Installation If you installed Open WebUI using Docker Compose, follow these steps to update: Pull the Latest Images: This command fetches the latest versions of the images specified in your docker-compose.yml files. docker compose pull Recreate the Containers with the Latest Images: This command recreates the containers based on the newly pulled images, ensuring your installation is up-to-date. No build step is required for updates. docker compose up -d This method ensures your Docker Compose-based installation of Open WebUI (and any associated services, like Ollama) is updated efficiently and without the need for manual container management.
Ref:Open WebUI 官方手册
Aider#
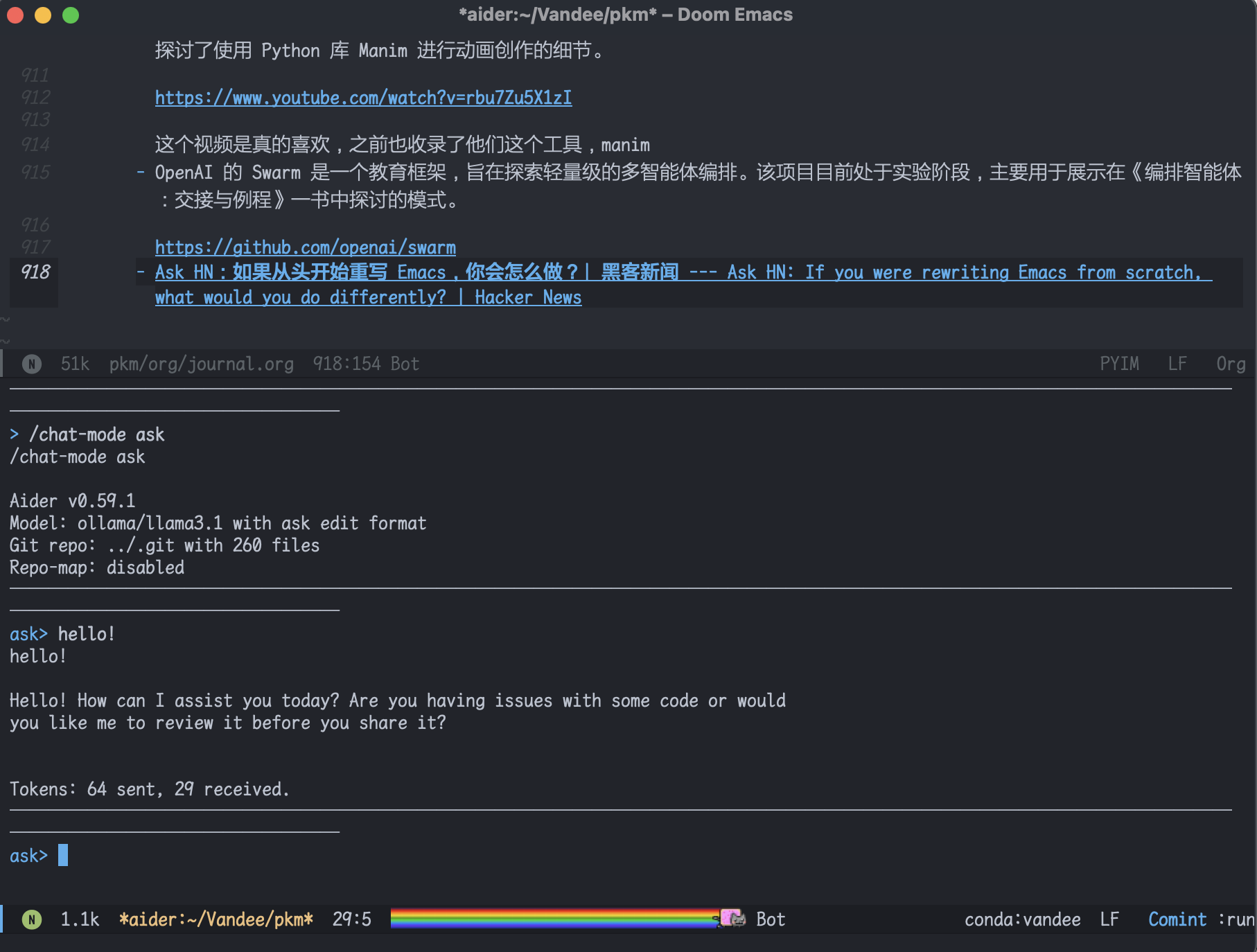
Aider 最近挺火的一个CLI AI助手,开源,GitHub 20.3K Star,基本可以支持市面上的所有模型。当然也支持ollama,在Emacs里有个大佬做了个aider.el。
可以像cursor一样有diff,修改代码,比之前看到的许多CLI AI助手(例如 gtpme、ai-shell 、cline 、claude-enginner)全面许多。
先在本机的Python环境里Install aider,我用的conda,在terminal里:
conda activate yourenv
python -m pip install -U aider-chat
实测在doomEmacs里要使用ollama的本地模型需要这样写:
(use-package aider
:config
(setq aider-args '("--model" "ollama/llama3.1"))
(setenv "OLLAMA_API_BASE" "http://127.0.0.1:11434")
(global-set-key (kbd "C-c a") 'aider-transient-menu)
)
另外在package.el里的安装:
(package! aider
:recipe (:host github :repo "tninja/aider.el" :files ("aider.el")))
在Emacs里激活conda环境正常运行Aider.el。
Ref:抛砖引玉: 介绍命令行AI编程工具aider以及emacs集成aider.el - Emacs-general - Emacs China
gptel#
gptel: A simple LLM client for Emacs 是Emacs的一个包,可以在Emacs里直接和LLM对话,目前在用。
最近更新了,可以支持直接添加文件、文本到上下文,awesome!居然还支持转换MD格式到Org?
您可以使用 gptel 的查询包含其他文本区域、缓冲区或文件。这个附加上下文是“实时”的,而不是快照。添加后,将在每次查询时扫描并包含区域、缓冲区或文件。
您可以从菜单中将选定的区域、缓冲区或文件添加到 gptel 的上下文中,或调用 gptel-add 。 (要添加文件,请在 Dired 中使用 gptel-add 或使用专用的 gptel-add-file 命令。)
Ref: https://github.com/karthink/gptel?tab=readme-ov-file#include-more-context-with-requests
| To add context 添加上下文 | |
|---|---|
gptel-add | Add/remove a region or buffer to gptel’s context. Add/remove marked files in Dired. 在 gptel 上下文中添加/删除区域或缓冲区。在 Dired 中添加/删除标记的文件。 |
gptel-add-file | Add a (text-readable) file to gptel’s context. Also available from the transient menu. 将(文本可读)文件添加到 gptel 的上下文中。也可以从瞬态菜单中获得。 |
;;基本配置
(use-package! gptel
:config
(setq! gptel-api-key "your key"))
or
;; :key can be a function that returns the API key.
(gptel-make-gemini "Gemini" :key "YOUR_GEMINI_API_KEY" :stream t)
or
;; Perplexity offers an OpenAI compatible API
(gptel-make-openai "Perplexity" ;Any name you want
:host "api.perplexity.ai"
:key "your-api-key" ;can be a function that returns the key
:endpoint "/chat/completions"
:stream t
:models '(;; has many more, check perplexity.ai
"pplx-7b-chat"
"pplx-70b-chat"
"pplx-7b-online"
"pplx-70b-online"))
or
;; Ollama
(gptel-make-ollama "Ollama" ;Any name of your choosing
:host "localhost:11434" ;Where it's running
:stream t ;Stream responses
:models '("mistral:latest")) ;List of models
Khoj AI#
Khoj AI 支持Docker、本地部署,目前GitHub 7.5k 12k star,天天都在涨。
支持PDF,纯文本,Markdown,org模式文件,notion页面和Github存储库、obsidian、Emacs、桌面客户端、web、phone、WhatsApp。同样支持ollama,很全能。
它的web版本方便好用,本地部署的版本不能和本地文档链接(模型是离线的,支持ollama和Hugging Face )。想要结合自己的本地的文档问答的话,需要申请khoj的API和khoj-cloud账号链接,也就是说不是完全的本地化,但是可以免费使用GPT-4o和claude-sonnet,还不需要代理,还要啥自行车?
Emacs的版本非常不好用,对话是一次性的,问了一个问题之后,就要重新输入一次命令。但是可以用自然语言检索本地文档,支持org文档的AI应用目前真的不多。
桌面版有一个唤起小窗口的功能挺好用:

要使用它,您只需复制要注入到查询中的文本,然后运行 Ctrl + Shift + K (或 Mac 上的 Cmd + Shift + K )即可打开迷你聊天模块。您复制的文本将自动粘贴到聊天模块中,然后您可以按 Enter 键获取答案。如果您想优化查询,可以在按 Enter 键之前编辑文本。
官方简介:
Welcome to the Khoj Docs! This is the best place to get setup and explore Khoj’s features.
欢迎来到Khoj!这是最好的地方得到设置和探索Khoj的功能。
Khoj is an open source, personal AI
Khoj是一个开源的个人AI
You can chat with it about anything. It’ll use files you shared with it to respond, when relevant
你可以和它聊任何事。它将使用您与它共享的文件来响应,当相关时
Quickly find relevant notes and documents using natural language
使用自然语言快速查找相关笔记和文档
It understands pdf, plaintext, markdown, org-mode files, notion pages and github repositories
它可以理解PDF,纯文本,Markdown,org模式文件,notion页面和Github存储库
Access it from your Emacs, Obsidian, Web browser or the Khoj Desktop app
从Emacs、Obsidian、Web浏览器或Khoj Desktop应用程序访问它
Use cloud to access your Khoj anytime from anywhere, self-host on consumer hardware for privacy
使用云随时随地访问您的Khoj,在消费者硬件上自行托管以保护隐私
Reor#
reor 是一个桌面客户端,目前GitHub 6.2k star。可根据本地md文档内容结合本地LLM问答。支持ollama。
注意不要直接使用原笔记的文件夹,在处理数据的时候可能会更改内容的格式,我有几个md文档的yaml头在识别- - -的时候出现了问题。
用了一段时间了,在mac上的体验只能说一般,对中文的RAG优化不是很好。
Dify#
Dify是一个支持本地部署的,兼容多方LLM平台(当然也支持ollama的本地模型)的,LLM-agent构建系统,约等于开源的扣子,目前GitHub 38.2K star。把本地的笔记加入到知识库,再用模板构建一个问答机器人助手,就可以简单的把本地笔记和LLM链接起来了。当然它可以做的太多了,爬取rss订阅、爬取新闻分类摘要,还在研究。
bestblogs.dev 就是一个很好的Dify案例: BestBlogs.dev 基于 Dify Workflow 的文章智能分析实践
官方简介:
你或许可以把 LangChain 这类的开发库(Library)想象为有着锤子、钉子的工具箱。与之相比,Dify 提供了更接近生产需要的完整方案,Dify 好比是一套脚手架,并且经过了精良的工程设计和软件测试。
重要的是,Dify 是开源的,它由一个专业的全职团队和社区共同打造。你可以基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活和安全的基础上,同时保持对数据的完全控制。
我们的社区用户对 Dify 的产品评价可以归结为简单、克制、迭代迅速。 ——路宇,Dify.AI CEO
docker部署
克隆 Dify 源代码至本地。
git clone https://github.com/langgenius/dify.git进入 Dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker cp .env.example .env docker compose up -d
Ref:
Kotaemon#
从发现到现在差不多就一个多星期,GitHub直接飙升到10.9K star,win、mac、Linux都支持。边用边学习它的RAG构建框架,支持ollama,支持docker。
GitHub: https://github.com/Cinnamon/kotaemon
Hugging Face 在线体验: https://huggingface.co/spaces/cin-model/kotaemon-demo
官方介绍:
This project serves as a functional RAG UI for both end users who want to do QA on their documents and developers who want to build their own RAG pipeline.
- For end users:
- A clean & minimalistic UI for RAG-based QA.
- Supports LLM API providers (OpenAI, AzureOpenAI, Cohere, etc) and local LLMs (via
ollamaandllama-cpp-python). - Easy installation scripts.
- For developers:
- A framework for building your own RAG-based document QA pipeline.
- Customize and see your RAG pipeline in action with the provided UI (built with Gradio).
- If you use Gradio for development, check out our theme here: kotaemon-gradio-theme.
ChangeLog#
2024-09-13: 校对文档。在使用了Nvim做MD笔记一个月之后,还是割舍不了org-mode的编辑体验,还有agenda。lisp的可玩性比lua还是高一些,比如dot-emacs/lisp/org-roam-logseq.el at master · jwiegley/dot-emacs这是一个把org-roam和Logseq联用的el。
How I Use “AI” 许多远古大佬还是在用Emacs,这点就足够我继续探索lisp的语言哲学了。orange.ai on X: “采访《汉语新解》作者李继刚:为什么会用 Lisp? ,最近大火的汉语新解的prompt就是lisp语法写的。
2024-10-09:更新了输入法设置,加入sis的配置方案。Open WebUI最近更新了,支持类似Claude artifacts的artifacts: 🎨 Artifacts Feature: Render web content and SVGs directly in the interface, supporting quick iterations and live changes.
还有一大堆新更新。
2024-10-13: 增加了 Aider (一个CLI AI编程助手)在Emacs里的安装,直接点击跳转到标题。最近开源的从代码到部署的 bolt.new 也很强,还有Pythagora的 gpt-pilot,AI辅助编程的项目越来越多了,感谢cursor带来了这么多的竞争者。
Thanks#
这个手册会持续更新,如果对你有所帮助,我会很开心。
这里是我日常使用的实用小工具: 实用小玩意收集
Imagining and creating!