脱离笔记软件,CLI笔记工具—nb
May 13, 2024 · 3151 words · 7 min · #PKM
AI摘要正在生成中……
PKM去形式化#
书接上回,现在的PKM第一原则是:数据的去形式化和通用性。只基于md文档的通用基础语法,其他功能以不污染文档内容的方式来实现。
为了实现这个目标,写了一些简单的bash脚本模板生成md,还有Emacs的Lisp函数做tag检索、文本查询,并将本地PKM-base库(最原子化的常青笔记)和Ollama对接(暂时用的是Reor)做一些思维扩展。卡在了md文档的全局引用和相对链接转换。
正愁着呢,在Github里无意中发现了一个宝藏!nb,牛逼!
nb#
我愿称其为最强CLI笔记工具!完美匹配我现在的所有需求,设计思路也和我不谋而合,还支持用Emacs做编辑器。虽然Emacs也可以通过自定义函数和插件来复现这些功能,但既然有现成的,就先copy吧🤣。
果然你能想到的99%都已经有人完成了101%。

macOS /Homebrew安装,brew install xwmx/taps/nb。nb也提供自己的shell,md预览可通过GUI web browsers,经常写md的基本也不需要预览。命令基本都是大白话,不需要刻意记忆,还提供Shortcut Aliases自定义命令 。nb不是一个笔记软件,是一个CLI工具,下面是nb的功能概览:
📝 Notes · Adding · Listing · Editing · Viewing · Deleting · 🔖 Bookmarks · ✅ Todos · ✔️ Tasks · 🏷 Tagging · 🔗 Linking · 🌍 Browsing · 🌄 Images · 🗂 Zettelkasten · 📂 Folders · 📌 Pinning · 🔍 Search · ↔ Moving & Renaming · 🗒 History · 📚 Notebooks · 🔄 Git Sync · ↕️ Import / Export · ⚙️``set&settings · 🎨 Color Themes · 🔌 Plugins · :/ Selectors · 01 Metadata · ❯ Shell · Shortcuts · ? Help · $ Variables · Specifications · Tests
去形式化之后的PKM#
bash脚本+nb实现,模板创建Daily和note,GUI web 预览:
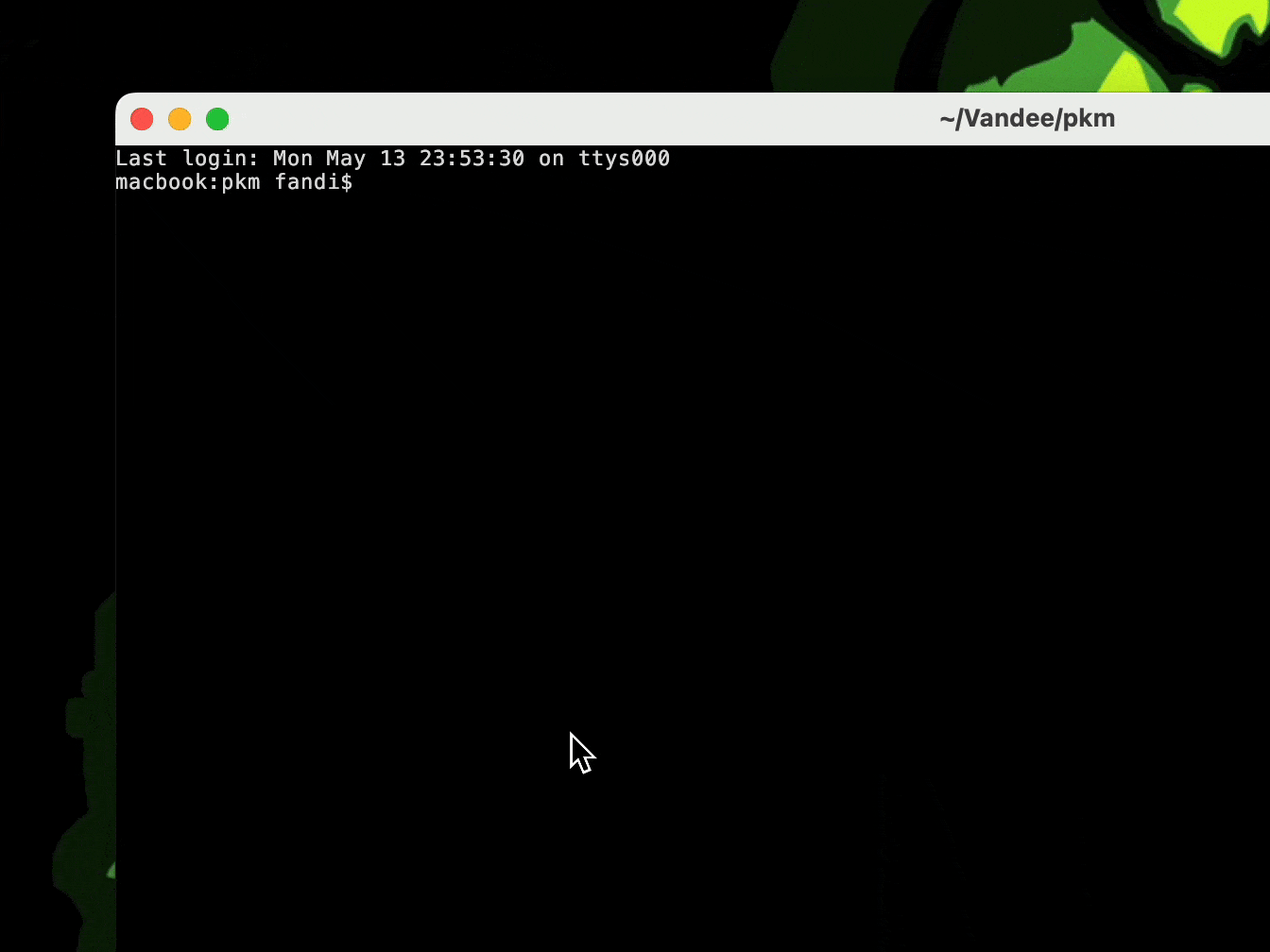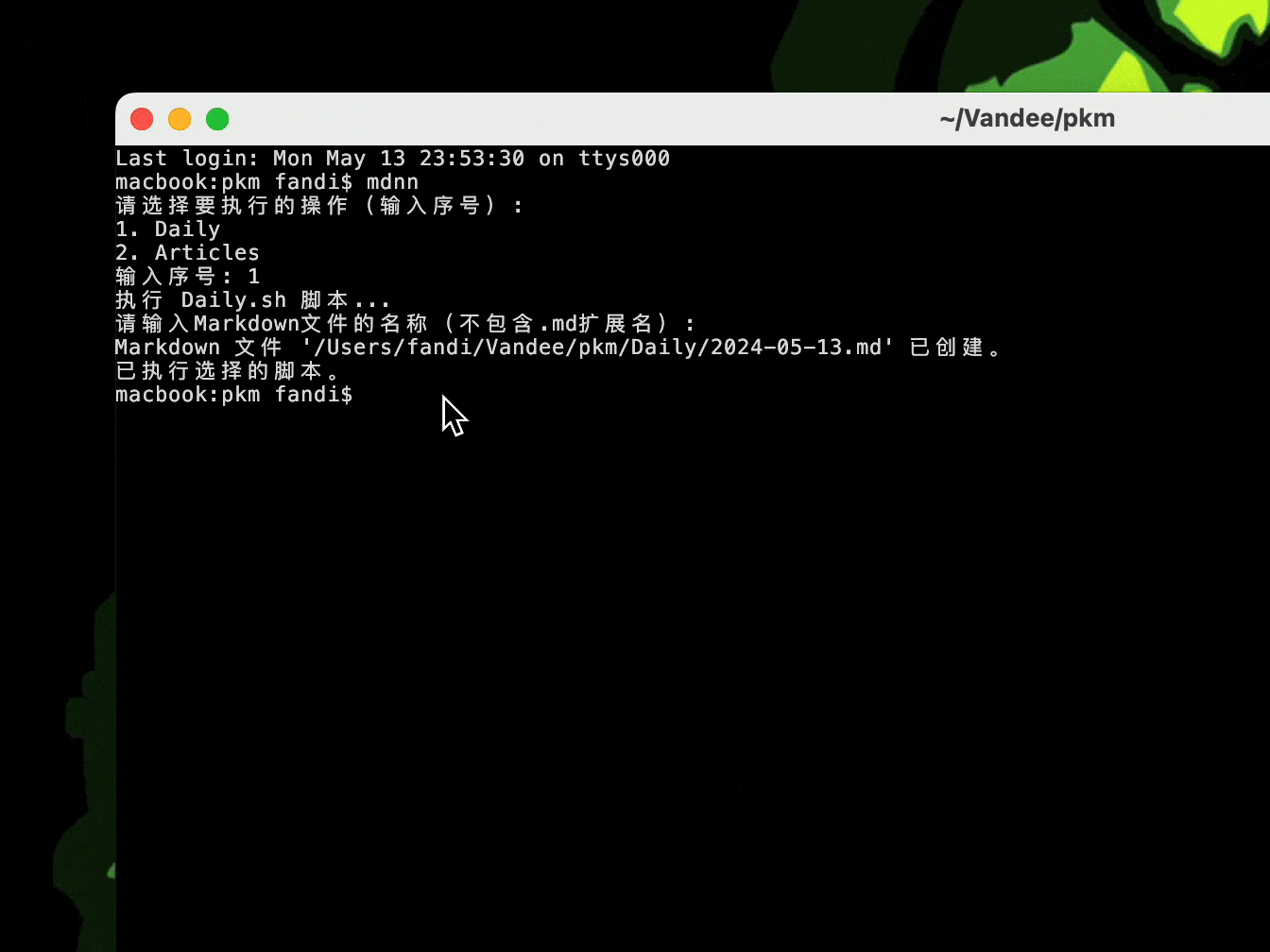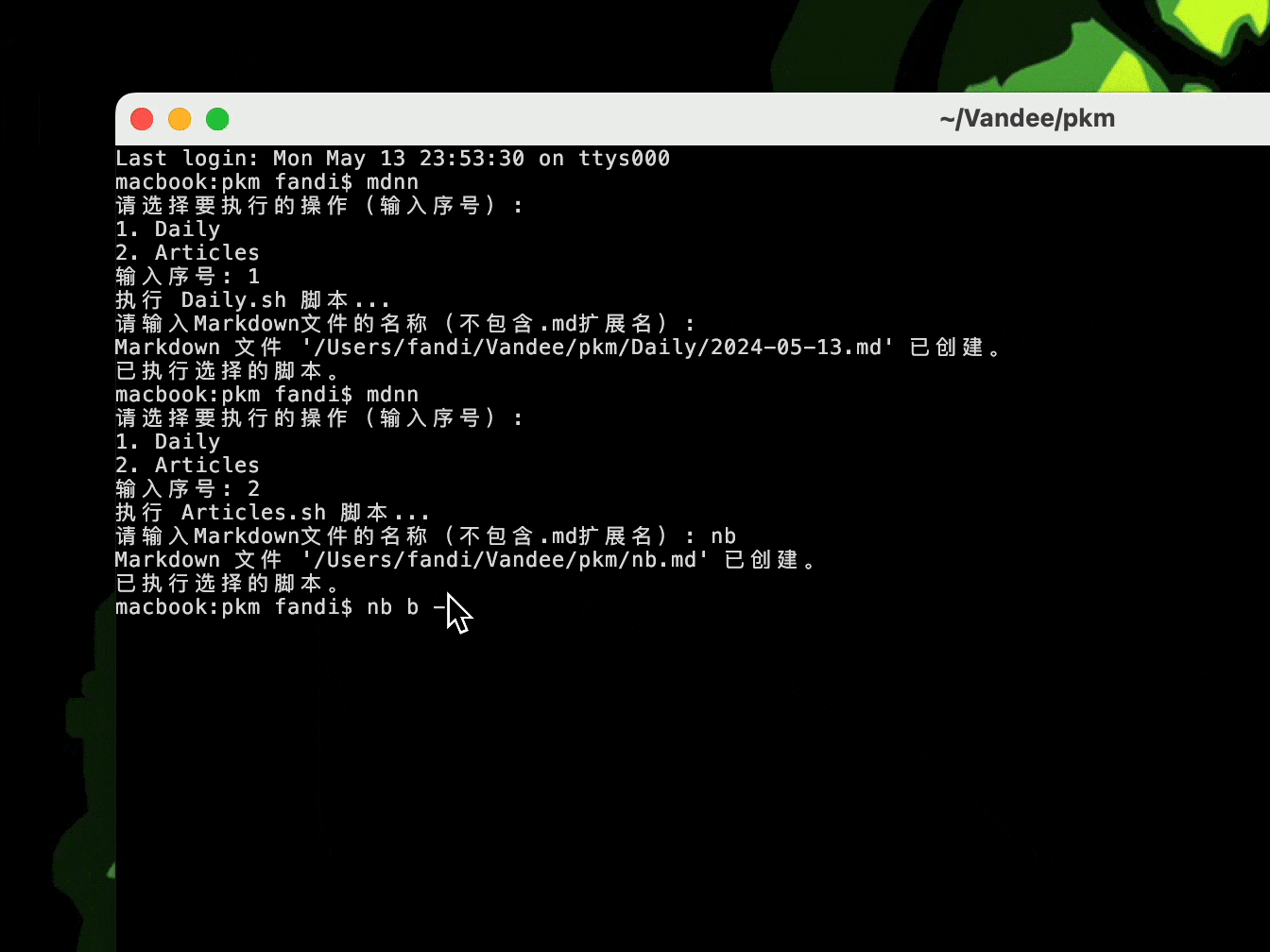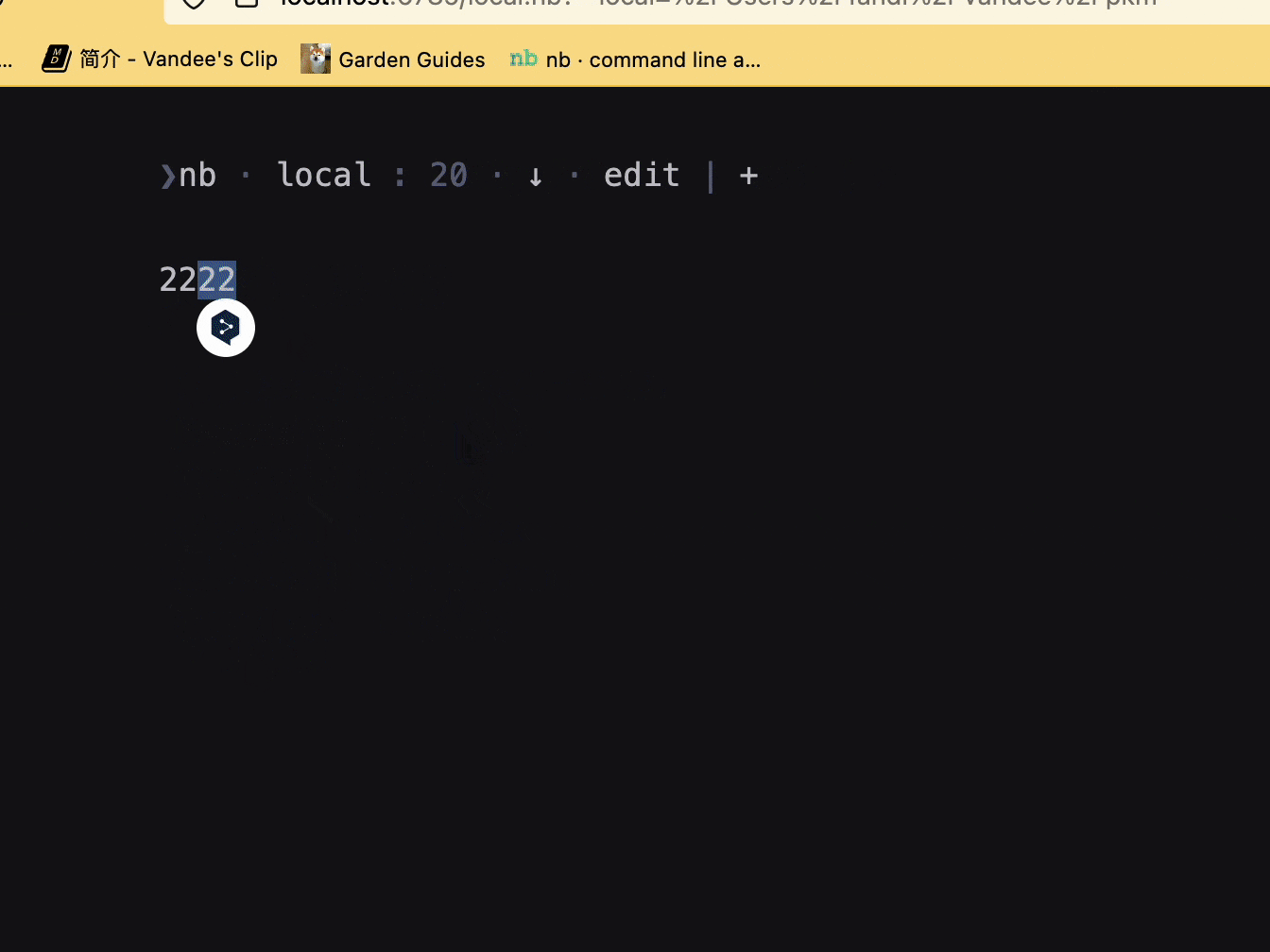
本地文档的双链、全局引用、tag、检索、查询、同步,这些关键功能现在都可以实现了,PKM脱离笔记软件初步达成。由于之前ob和Logseq联用保留了文件夹结构,现在还是沿用ACCESS结构换成nb和Emacs来管理,nb提供全局的检索和双链,Emacs做统筹(org-mode还在犹豫),部署就先用 Quartz v4.2.3 ,暂时当作我的数字花园,欢迎来玩!Blog练笔,Clip剪藏,Garden做wiki。目前还是不太想all in one ,以后可能会做个后端数据库。
至于Logseq和 ob以及其他笔记软件里的通过块ID来引用块、嵌入块,查询语句,通过css和js实现的排版样式等,这些通过非md标准语法实现的功能,全部舍弃。尽最大可能减少笔记元数据转化为其他形式的成本,它应该可以独立于笔记软件又具备优秀的兼容性。
这些在各种笔记软件里实现的个性化功能,比如白板、卡片、思维导图,当然提升了信息处理的效率,但最核心的还是双链,以及思维的同步率。
把人自身的思维看作一个向量,它有自己的方向和属性,在大脑里让它们串联起来的是一个个神经元和突触,在笔记里就是双链和索引。因此,要在PKM里最大程度复现大脑思维的流动,我认为,最自然的方式就是让笔记向量与思维最自然的习惯同步。
例如我们的语言系统,我们不会在用母语表达一些简单想法的时候还费力思考,笔记也应该是一样。当我大脑里现在想到一个概念,需要在笔记里找到相应的内容,脱口而出时,就应该只需要按照思维本来的习惯检索到笔记。
比如我现在想表达:王小波牛逼!在PKM里我只需要输入王小波牛逼这个一模一样的内容,和这个向量相关的信息都会以双链链接起来,而不需要我再按照tag做二级查询,通过属性反过来找概念。这些tag标注的是向量的属性以便做复杂的分类和列举,例如《黄金时代》,文学,王小波,这些在大脑里自然联系起来的概念,不应该在笔记查询的时候再做重复的检索,我不需要反过来通过查询文学、王小波,来找到《黄金时代》,然后再找到我想在书里表达的概念。而是自然的通过和王小波牛逼这个概念同步联系起来的反链呈现。这就要求原子笔记里的概念有极高的抽象程度以及自身思维习惯同步率。
解决了这个问题,我觉得无论笔记形式怎么变,用什么笔记软件,思维向量的生命周期就可以在这些形式里延长。
Notion,Obsidian,Logseq,再到现在,我更加确定,下一个笔记软件何必是笔记软件。
至于为什么一直折腾做笔记这件事,因为思维的具象化一直是这几年我着重思考的问题,平常思考的哲学和艺术都是它的分支,它们都是思维抽象而成的具象表达。思维呈现的效果和处理的效率都和做笔记正相关,也同样作用于认知。现在正处于量变的积累过程,效率就更加重要了。现在的PKM可以让我的思维向量更好的碰撞,因为高度同步于我自身的思维,它们在数据里延续着生命,自发地碰撞出思维的电子火花。这一点经过一年的折腾已经得到验证。
之前说要通过这些具象化的思维材料复刻一个自己的数字人,可得捏的像一些。
Logseq适配Quartz#
这次在logseq格式转化的时候,几个问题小折腾了一会。
七拼八凑了一下,下面是用GPT缝合的,Logseq重新排版批量输出为md格式的Python代码。这段代码会把Logseq文档头部的key:: value 格式化为标准的yaml格式并去除标题前面的无序列表符号。Logseq本身可以输出text但排版不是很完美,也不方便。Logseq和ob联用的兄弟们应该用得上。
# -*- coding = utf-8 -*-
# @Project : Logseq标题优化
# @File : Logseq格式优化.py
# @time : 2024/05/11
# @Author : Vandee
# @Description :适合yaml为Logseq的::样式
import re
import os
# Frontmatter consts for start and end of Frontmatter YAML heading in Markdown
FRONTMATTER_START_STR = "---\n"
FRONTMATTER_END_STR = "---\n\n"
FRONTMATTER_PARAM_NAME_REGEXP: str = r"[A-Za-z0-9-_.]+::\s"
LOGSEQ_LIST_REGEXP: str = r"^[\s\t]*- "
def load_logseq_sanitized(file_path: str, encoding: str = "utf-8") -> list[str]:
with open(file_path, "r", encoding=encoding) as f:
lines: list[str] = f.readlines()
return_lines: list[str] = []
for line in lines:
# we skip empty lines
if line in ("\n", "- \n", "-\n", "- \n"):
continue
# we remove "- " or " " from the beginning of line as
# it's Logseq specific "everyghing is a list" approach
if line.startswith(("- ", " ")):
line = line[2:]
# we remove first occurance of tab character ("\\t") from a line as
# it's indicating list item
if line.startswith("\t"):
line = line.replace("\t", "", 1)
return_lines.append(line)
return return_lines
def logseq2markdown(logseq_lines: list[str]) -> str:
"""Goes through list of Logseq sanitized lines (provided by `load_logseq_sanitized()`) and
translates them to proper Markdown and Frontmatter.
Args:
logseq_lines (list[str]): List of sanitized lines from Logseq file loader
Returns:
str: String containing Frontmatter header in YML format followed by proper Markdown.
"""
mk_content: list[str] = []
# Using dict here as we don't want to have duplicate parameter names in Frontmatter
# (each should have unique indentifier).
mk_frontmatter: dict[str, str] = {}
param_regex = re.compile(FRONTMATTER_PARAM_NAME_REGEXP)
logseq_list_regexp = re.compile(LOGSEQ_LIST_REGEXP)
for line in logseq_lines:
params_result = param_regex.findall(line)
logseq_list_result = logseq_list_regexp.findall(line)
# if line containts "logseq.order-list-type:: number" it should be
# numbered list and this line should be ommited
if -1 != line.find("logseq.order-list-type:: number"):
line = mk_content.pop()
line = line.lstrip("\n")
line = line.replace("- ", "1. ", 1)
line = line.replace("\t", " ")
mk_content.append(line)
# if line containts "logseq.order-list-type:: bulllet" it should be
# bullet point list and this line should be ommited
elif -1 != line.find("logseq.order-list-type:: bullet"):
line = mk_content.pop()
line = line.lstrip("\n")
line = line.replace("- ", "* ", 1)
line = line.replace("\t", " ")
mk_content.append(line)
# if line is proper unordered list we parse it as such
elif logseq_list_result:
line = line.lstrip("\n")
line = line.replace("\t", " ")
mk_content.append(line)
# if line starts with "# " (meaning h1 in html) we parse it as Frontmatter "title:" param
elif line.startswith("# "):
mk_frontmatter["title"] = '"' + line[2:].strip() + '"'
# if line doesn't have any Logseq-specific parameters like numbered or bullet list in it
# and has Frontmatter param format we add it to Frontmatter header
elif params_result:
mk_frontmatter[params_result[0][0:-3]] = line[len(params_result[0]) :]
# otherwise we add it to content as any other Markdown element
else:
mk_content.append("\n" + line)
return_string: str = ""
if mk_frontmatter:
return_string = (
FRONTMATTER_START_STR
+ "\n".join(
[
f"{fm_item[0]}: {fm_item[1].strip()}"
for fm_item in list(mk_frontmatter.items())
]
)
+ "\n"
+ FRONTMATTER_END_STR
)
return return_string + "".join(mk_content)
def process_folder(input_folder: str, output_folder: str):
"""处理输入文件夹中的文件,并将结果导出到输出文件夹。
Args:
input_folder (str): 输入文件夹路径。
output_folder (str): 输出文件夹路径。
"""
# 确保输出文件夹存在,如果不存在则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历输入文件夹中的每个文件
for file_name in os.listdir(input_folder):
if file_name.endswith(".md"): # 仅处理以 .md 结尾的文件
input_file_path = os.path.join(input_folder, file_name)
output_file_path = os.path.join(output_folder, file_name)
# 加载、处理和导出文件
logseq_lines = load_logseq_sanitized(file_path=input_file_path)
markdown_content = logseq2markdown(logseq_lines)
# 将转换后的内容写入到输出文件中
with open(output_file_path, "w", encoding="utf-8") as f:
f.write(markdown_content)
print(f"文件 '{file_name}' 已处理并导出到 '{output_folder}'")
# 主程序中使用命令行提示用户输入文件夹路径
if __name__ == "__main__":
# 提示用户输入输入文件夹路径
input_folder = input("请输入输入文件夹路径:")
# 提示用户输入输出文件夹路径
output_folder = input("请输入输出文件夹路径:")
process_folder(input_folder, output_folder)
处理之后,Logseq库接近700个文档99%的排版都没问题,部分三级列表以上的复杂排版,列表会多出一些空行或层级错位,Logseq复杂排版的换行和简单的\r\n还是有区别。可能也有CRLF和LF的问题,mac和win互相git,脚本里用的是LF,如果你是win最好还是\r\n。Quartz在转换md到html的时候换行逻辑不一样,在Typora里看是有换行的,但是Quartz部署成网页之后部分换行就没了。
yaml区域的逻辑可以再用yaml库优化,后面再完善这个格式化脚本来把任意其他排版统一成我的标准样式。