Clip—数字花园的又一枝花
Apr 29, 2024 · 1616 words · 4 min · #PKM #Blog #Hugo
AI摘要正在生成中……
现在已弃用,感觉和数字花园有些重复,原clip剪藏的文章现在通过org-capture结合org-agenda保存在单独的clip.org文件里,然后整理输出到 Articles | Vandee’s Digital Garden,同样支持RSS订阅。
Clip#
很早以前用Notion、MarkDownload剪藏,但一直用的很膈应,苦于没有一个好的工具,直到现在才发现 Owen’s Clip 这个项目。太符合我的需求了,马不停蹄copy下来。
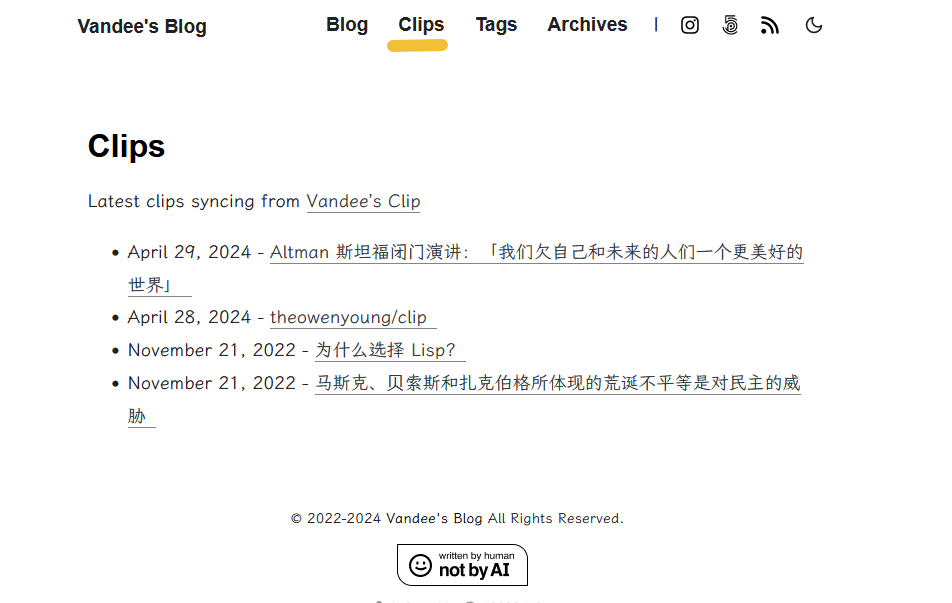
前段时间才在考虑用Omnivore把网页阅读、订阅和剪藏的流程优化一下,开源Logseq里的部分笔记,正在折腾jina-ai-reader现在可以先用Vandee’s Clip了。这里会实时更新剪藏的文章,支持Rss订阅,还可以生成Eqube电子书。把Clip也放在了Vandee’s Blog的Clips里。同步更新Clip里的前10个最新文章。
做知识管理最忌讳本末倒置,但顺其自然的折腾绝不是在浪费时间,blog也好,clip也好,恰恰是在整合知识,实践知识,恰恰是因为认知和需求在不断交汇,碰撞出新的需求。这些能让思维和知识真正的流动起来,随之增长的认知,再实践,形成良性循环。一个idea,如何一步步整合成现实,加入自己风格、理念、哲学,这正是创造,对此我总是乐此不疲。
下一个笔记软件何必是笔记软件。现在我的数字花园、PKM的架构是:编辑器Emacs,知识检索Logseq,笔记开源Blog、Clip。Clip这部分加入到我的PKM之后,会是以后读书会和个人电子书的雏形(都没脸提这个已经搁置了一年的项目了🤣)。
真正的知识就应该是开源的,它是属于全人类的,好的东西,就应更让更多人看到,这正是分享的价值。最重要的是,这让我很快乐。
我的这点东西更没什么好吹嘘的,只是在解决这些问题的时候网上搜索到的,大部分都太闹眼子了,浪费了我很多时间,我只想分享点有用的东西给需要的人。正是其他一样乐于分享的人,让我发现了这些。

Blog折腾记录#
补充记录一下配置,做个备份。下面是hugo 的一些优化
解决Clip的同步#
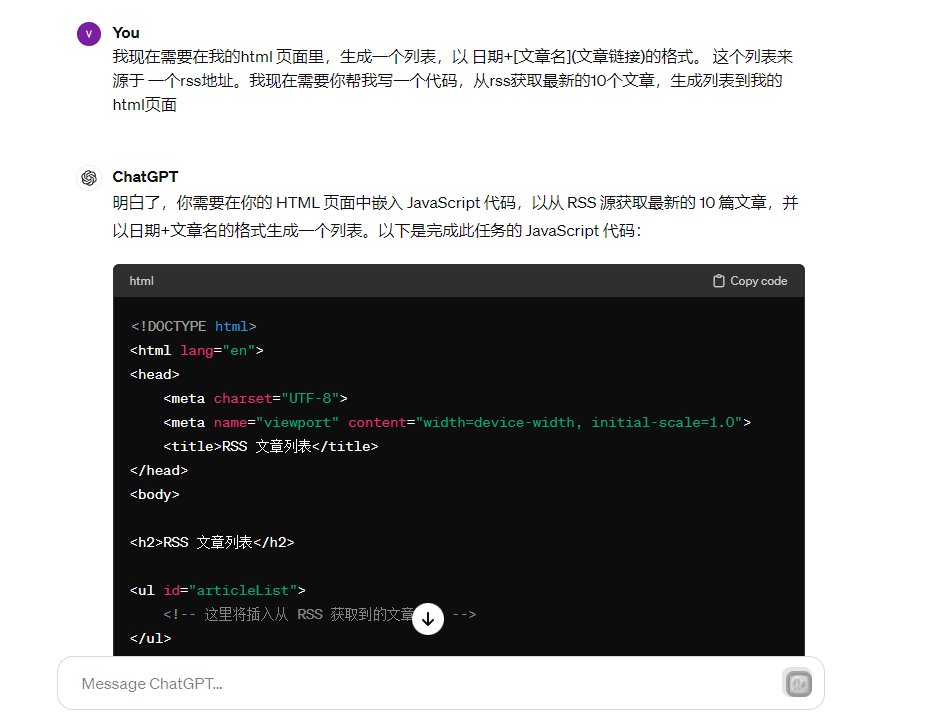
<h2>RSS 文章列表</h2>
<div id="clipList">
<p id="syncStatus">Syncing...</p>
<ul id="articleList" style="opacity: 0; transition: opacity 1s;">
<!-- 这里将插入从 RSS 获取到的文章列表 -->
</ul>
<style>
/* 自定义列表样式 */
#articleList li p,
#articleList li a {
display: inline; /* 将 p 和 a 标签设置为行内元素 */
# padding-right: 10px; /* 设置 p 标签和 a 标签之间的间距 */
}
</style>
<script>
// 目标网页的 RSS 地址
const rssUrl = 'https://clip.vandee.art/feed.xml';
// 获取当前日期的字符串表示,格式为 YYYY-MM-DD
const today = new Date();
today.setHours(0, 0, 0, 0); // 将时间部分设置为零时零分零秒
// 显示 "Syncing..." 文字
document.getElementById('syncStatus').style.display = 'block';
// 获取 RSS 数据并生成文章列表
fetch(rssUrl)
.then(response => response.text())
.then(xml => {
// 使用正则表达式提取每个 <entry> 部分的日期、标题和链接
const regex = /<entry>(.*?)<\/entry>/gs;
let match;
const recentArticles = [];
while ((match = regex.exec(xml)) !== null && recentArticles.length < 10) {
// 从 <entry> 部分中提取日期、标题和链接
const entry = match[1];
const pubDateMatch = /<updated>(.*?)<\/updated>/s.exec(entry);
const linkMatch = /<link href="(.*?)"/s.exec(entry);
const titleMatch = /<title type="html">\s*<!\[CDATA\[(.*?)\]\]>\s*<\/title>/s.exec(entry);
if (pubDateMatch && linkMatch && titleMatch) {
const pubDate = new Date(pubDateMatch[1]);
pubDate.setHours(0, 0, 0, 0); // 将时间部分设置为零时零分零秒
// 如果文章日期早于或等于今天,则将其添加到列表中
if (pubDate <= today) {
const formattedDate = pubDate.toLocaleDateString('en-US', { year: 'numeric', month: 'long', day: 'numeric' });
const link = linkMatch[1];
const title = titleMatch[1];
recentArticles.push({ pubDate: formattedDate, title, link });
}
}
}
// 对提取的文章按照日期从新到旧排序
recentArticles.sort((a, b) => new Date(b.pubDate) - new Date(a.pubDate));
// 生成文章列表
const articleList = document.getElementById('articleList');
recentArticles.forEach((article, index) => {
const listItem = document.createElement('li');
listItem.textContent = `${article.pubDate} - `;
const link = document.createElement('a');
link.href = article.link;
link.textContent = article.title;
listItem.appendChild(link);
articleList.appendChild(listItem);
// 当列表加载完毕后,显示列表并隐藏同步状态
if (index === recentArticles.length - 1) {
articleList.style.opacity = '1';
document.getElementById('syncStatus').style.display = 'none';
}
});
})
.catch(error => {
console.error('Error fetching or parsing RSS:', error);
});
</script>
</div>
GPT还是省事的,对于我这个只把js在菜鸟教程上过了一遍的人来说,自己写可能要一天。
fancybox#
给图片加上data-fancybox="gallery"属性。
// 获取文章中的img 标签 不包括封面
$('.blog-content img').not(".cover").each(function () {
//添加 data-fancybox="gallery"
$(this).attr("data-fancybox","gallery");
})
不蒜子优化#
参见:
不蒜子统计常见问题 - 辣椒の酱
Vercount: 一个比不蒜子更好的网站计数器 - EvanNotFound’s Blog
其他hugo代码#
<!-- 获取博客文章数量 -->
{{ len (where .Site.RegularPages "Section" "blog") }}
<!-- 获取博客Taxonomies -->
{{ range .Site..categories }}
# <a href="{{ .Page.Permalink }}">{{ .Page.Title }}</a>({{ .Count }})
{{ end }}
<!-- _markup/render-link.html 外链接新标签页打开 -->
{{- $u := urls.Parse .Destination -}}
<a href="{{ .Destination | safeURL }}" target="_blank"
{{- with .Title }} title="{{ . }}"{{ end -}}
{{- if $u.IsAbs }} rel="external"{{ end -}}
>
{{- with .Text | safeHTML }}{{ . }}{{ end -}}
</a>
{{- /* chomp trailing newline */ -}}
cdn
<!-- fancybox -->
{{ if .Site.Params.fancybox}}
<link rel="stylesheet" href="https://fastly.jsdelivr.net/npm/@fancyapps/ui@4.0.12/dist/fancybox.css">
<script src="https://fastly.jsdelivr.net/npm/@fancyapps/ui@4.0.12/dist/fancybox.umd.js"></script>
{{ end }}
<!-- jquery -->
<script src="https://lf6-cdn-tos.bytecdntp.com/cdn/expire-1-M/jquery/3.6.0/jquery.min.js"></script>
<!-- lazyload -->
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/lazyload/2.0.3/lazyload.js" type="application/javascript"></script>
<!-- pangu -->
<script src="https://lf3-cdn-tos.bytecdntp.com/cdn/expire-1-M/pangu/4.0.7/pangu.min.js"></script>
<!-- lxgw-wenkai -->
<link rel="stylesheet" href="https://cdn.bootcdn.net/ajax/libs/lxgw-wenkai-webfont/1.6.0/style.min.css" />